Status and future plans
animal2vec
A deep learning based framework for large scale bioacoustic tasks
Max Planck Institute of Animal Behavior
Department for the Ecology of Animal Societies
Communication and Collective Movement (CoCoMo) Group

Overall concept
The concepts
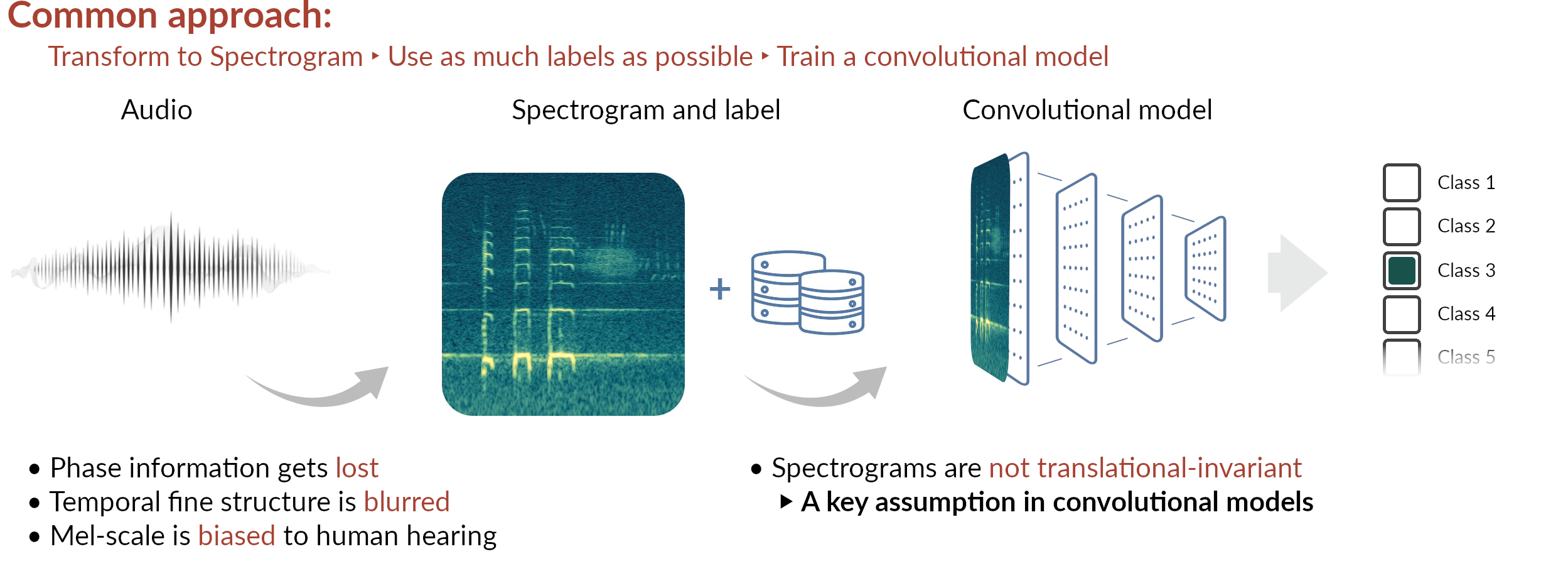
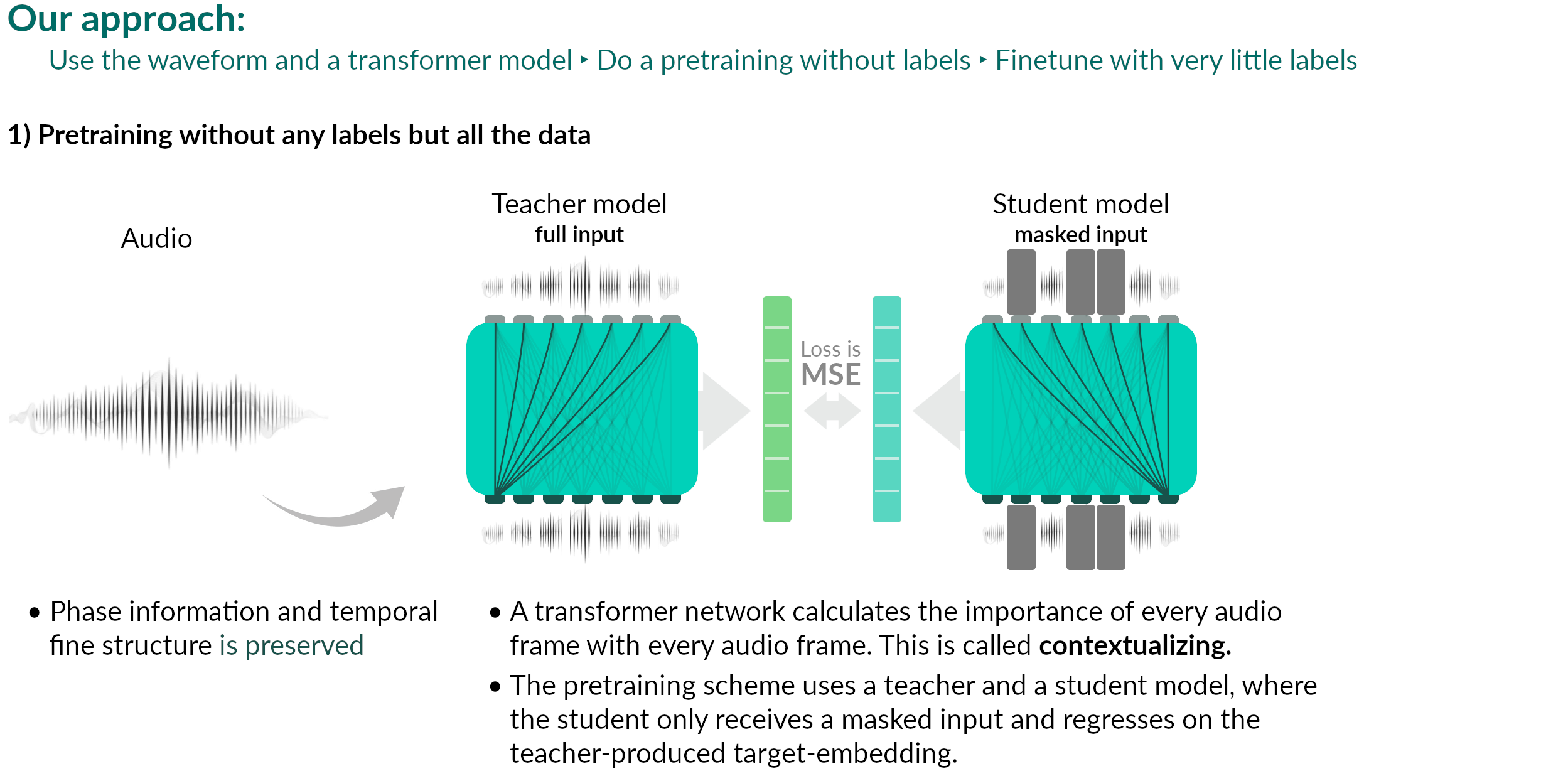
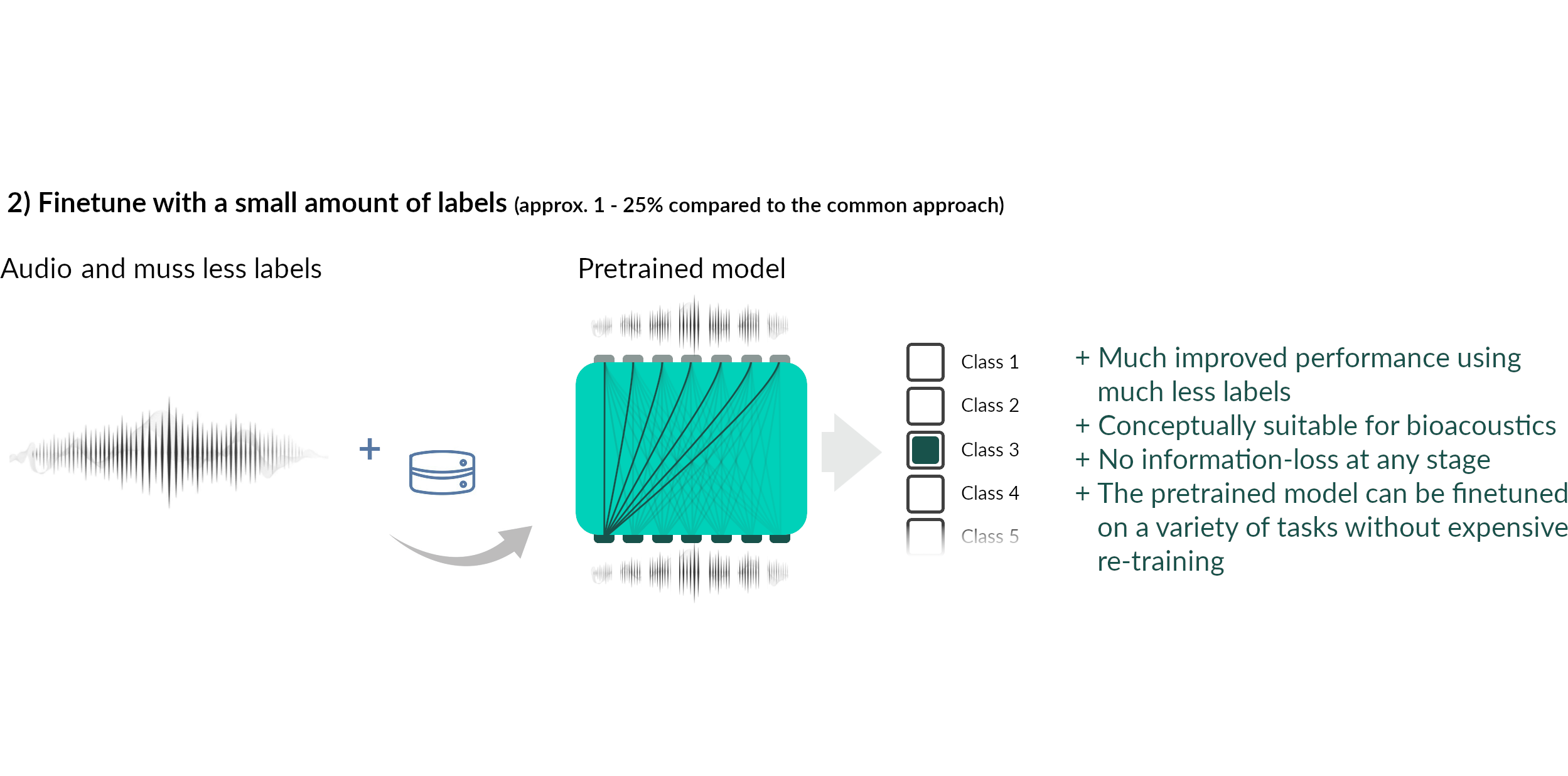
Current status
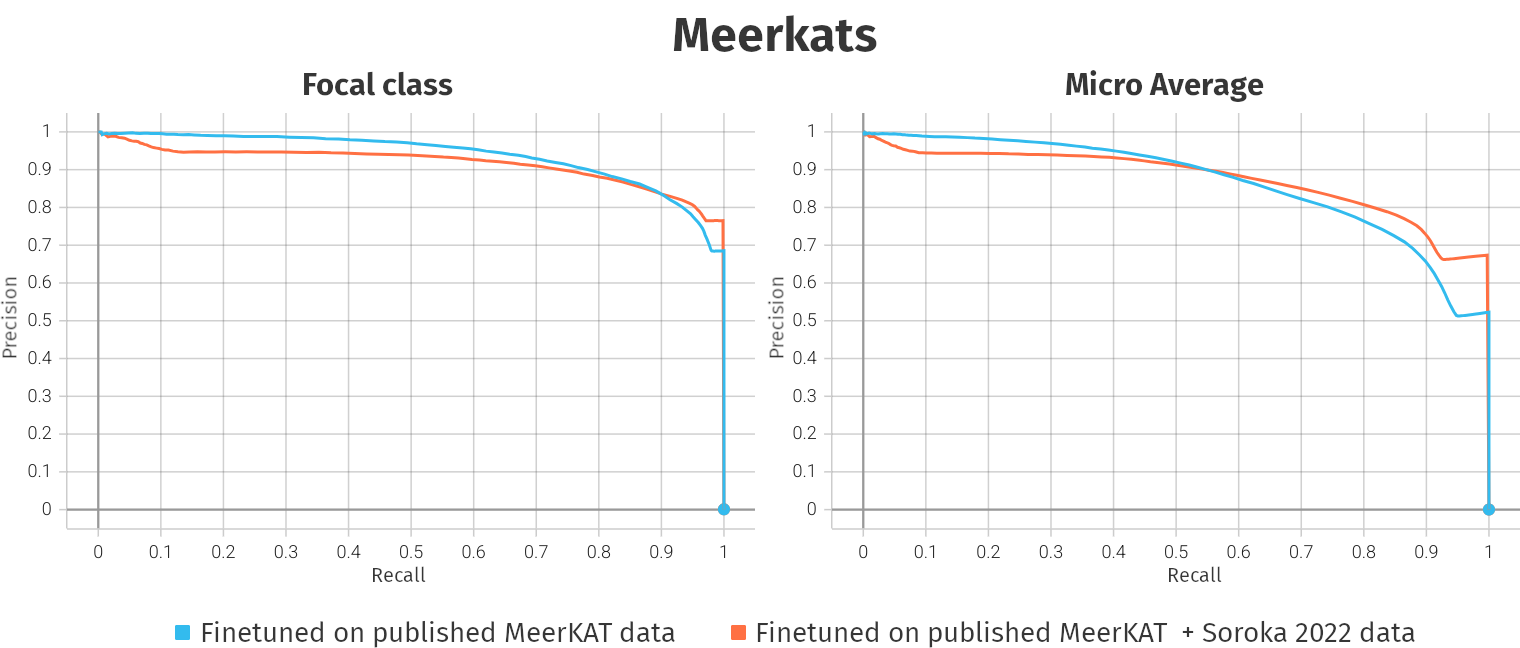
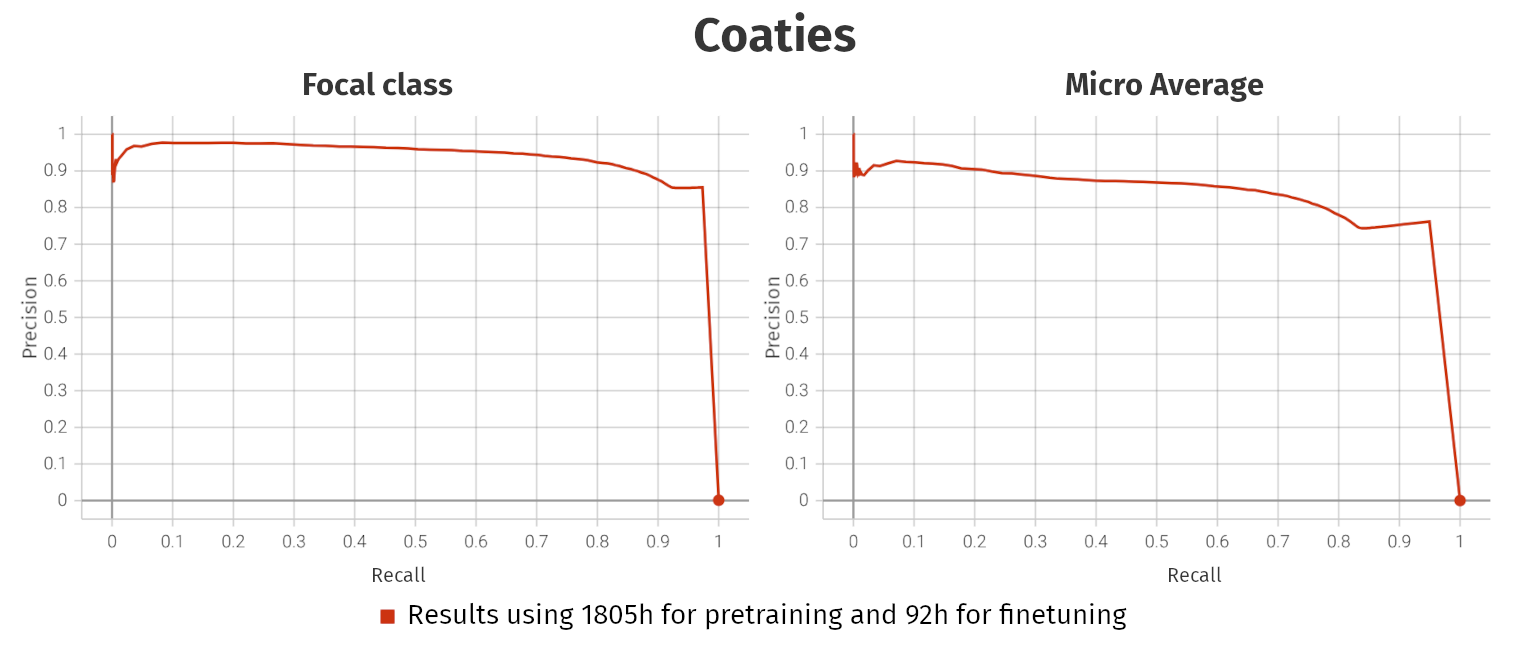
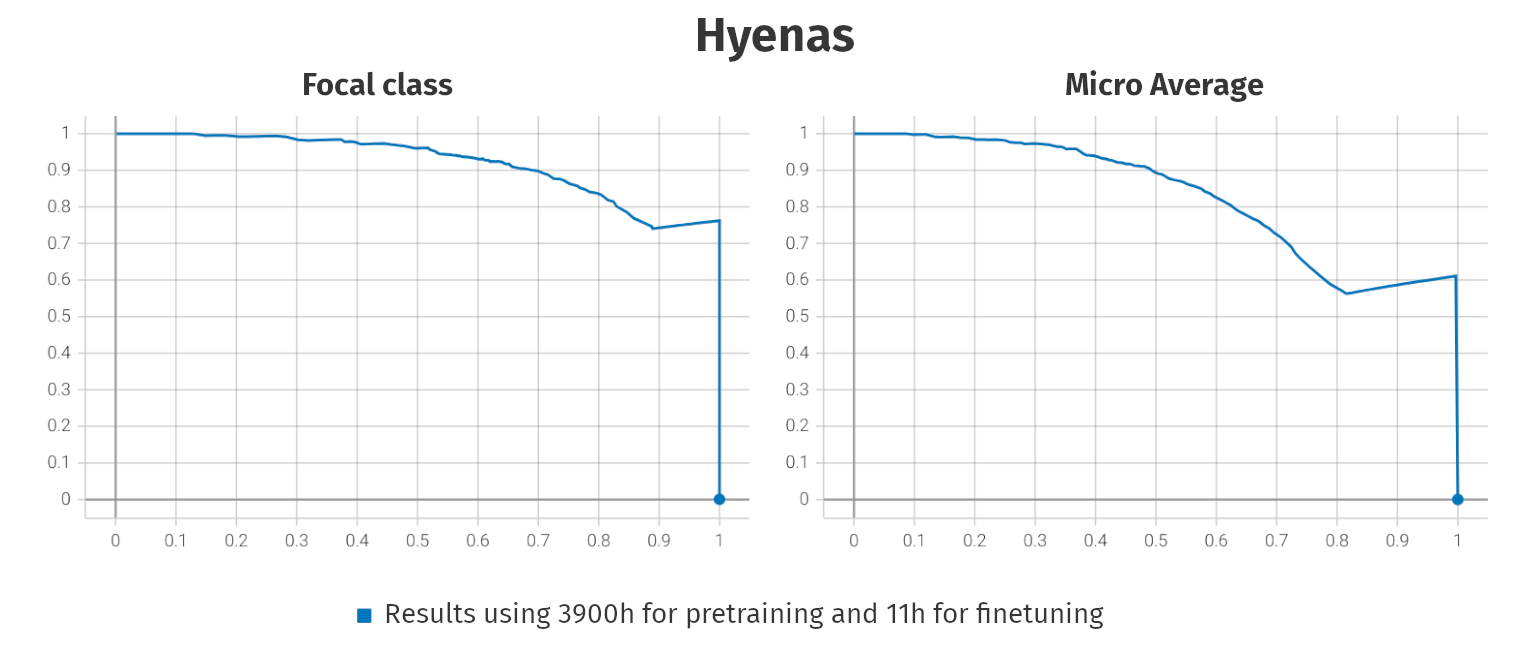
Meerkats, Coatis, Hyenas
- By now, we have predictions for all major species in the CCAS project
↪ Meerkats, Coatis, and Hyenas
animal2vec 2.0
The idea
- Currently, we train (pretrain + finetune) new models for every species
- Computationally very expensive
- Pretraining takes almost a month. Finetuning, a couple of days
- What is usually done in industry is to do a single extremely large-scale pretraining and then several smaller finetunes with different and smaller datasets
- The broadly pretrained model is then called foundational model
- Bioacoustic researchers, regardless of the species they study, could start from such a foundational model and finetune on the data they have
- For a lot of audio, we have coincident data-streams, like GPS, or Acc. from collars. We want to use that
animal2vec 2.0
Why don't we have that already?
Sparsity: Animal vocalizations are short and rare events
- For example:
- MeerKAT [1]: 184h of labeled audio, of which 7.8h (4.2%) contain meerkat vocalizations
- BirdVox-full-night [2]: 4.5M clips, each of duration 150 ms, only 35k (0.7%) are positive
- Hainan gibbon calls [3]: 256h of fully labeled PAM data with 1246 few-seconds events (0.01%)
- Marine datasets have even higher reported sparsity levels [4]
Engineering: It is not trivial to build a codebase for fault-tolerant mixed precision distributed training in a multi-node multi-GPU large-scale out-of-GPU-memory setting
I underestimated that
[1] Schäfer-Zimmermann, J. C., et al. (2024). Preprint at arXiv:2406.01253
[3] Dufourq, E., et al. (2021) Remote Sensing in Ecology and Conservation, 7(3), 475-487.
[4] Allen, A. N., et al. (2021) Frontiers in Marine Science, 8, 607321
animal2vec 2.0
Why don't we have that already?
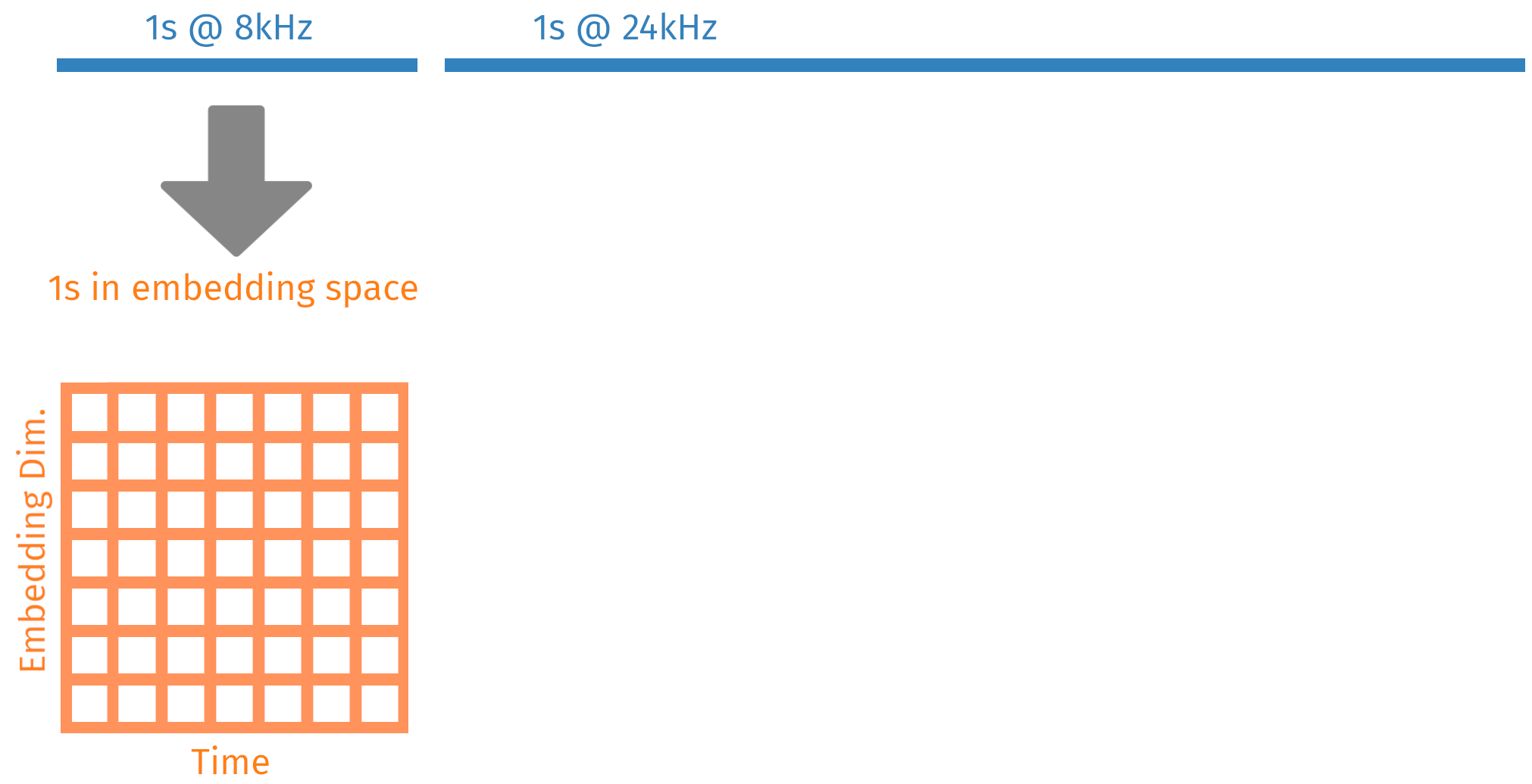
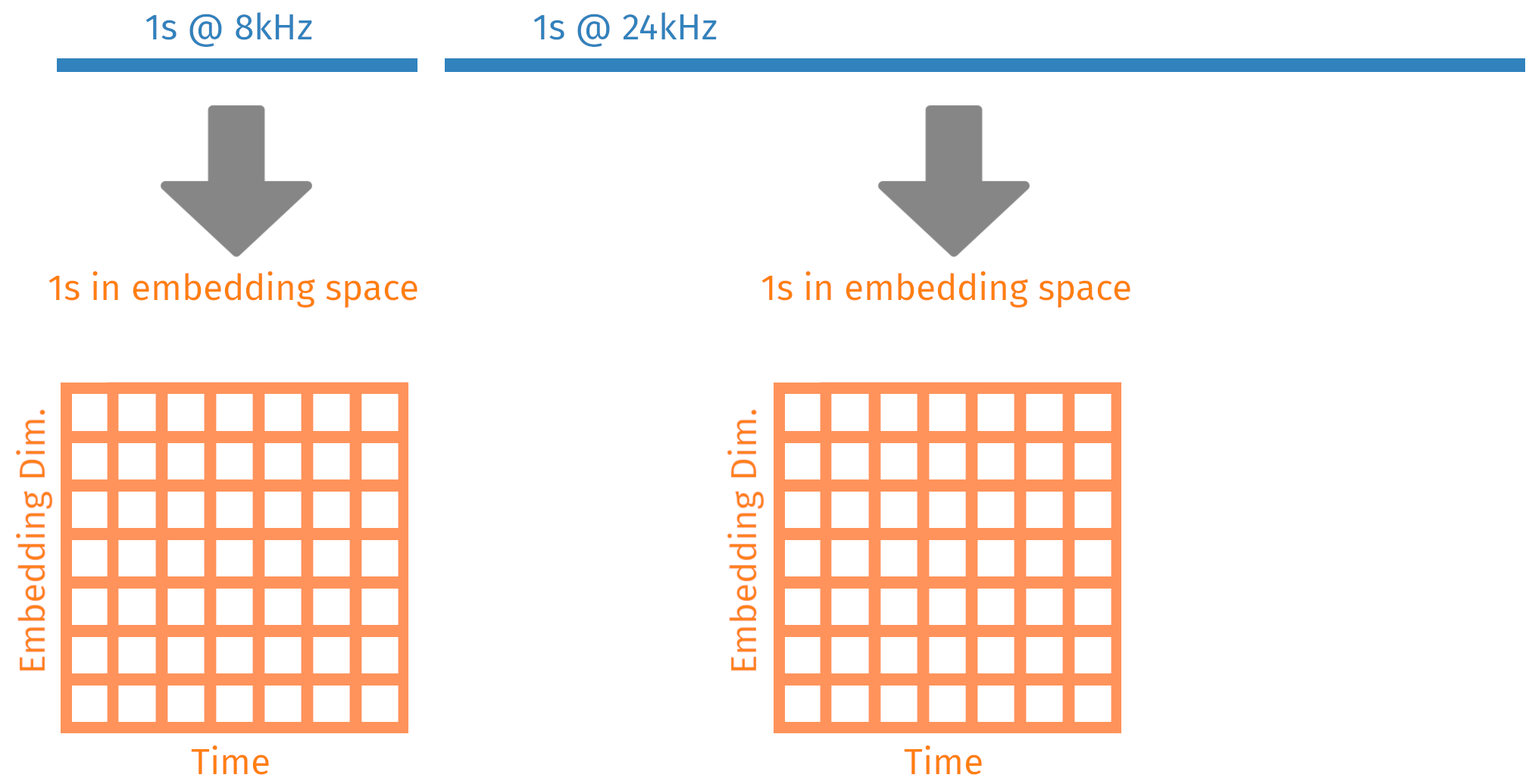
Differing sample rates
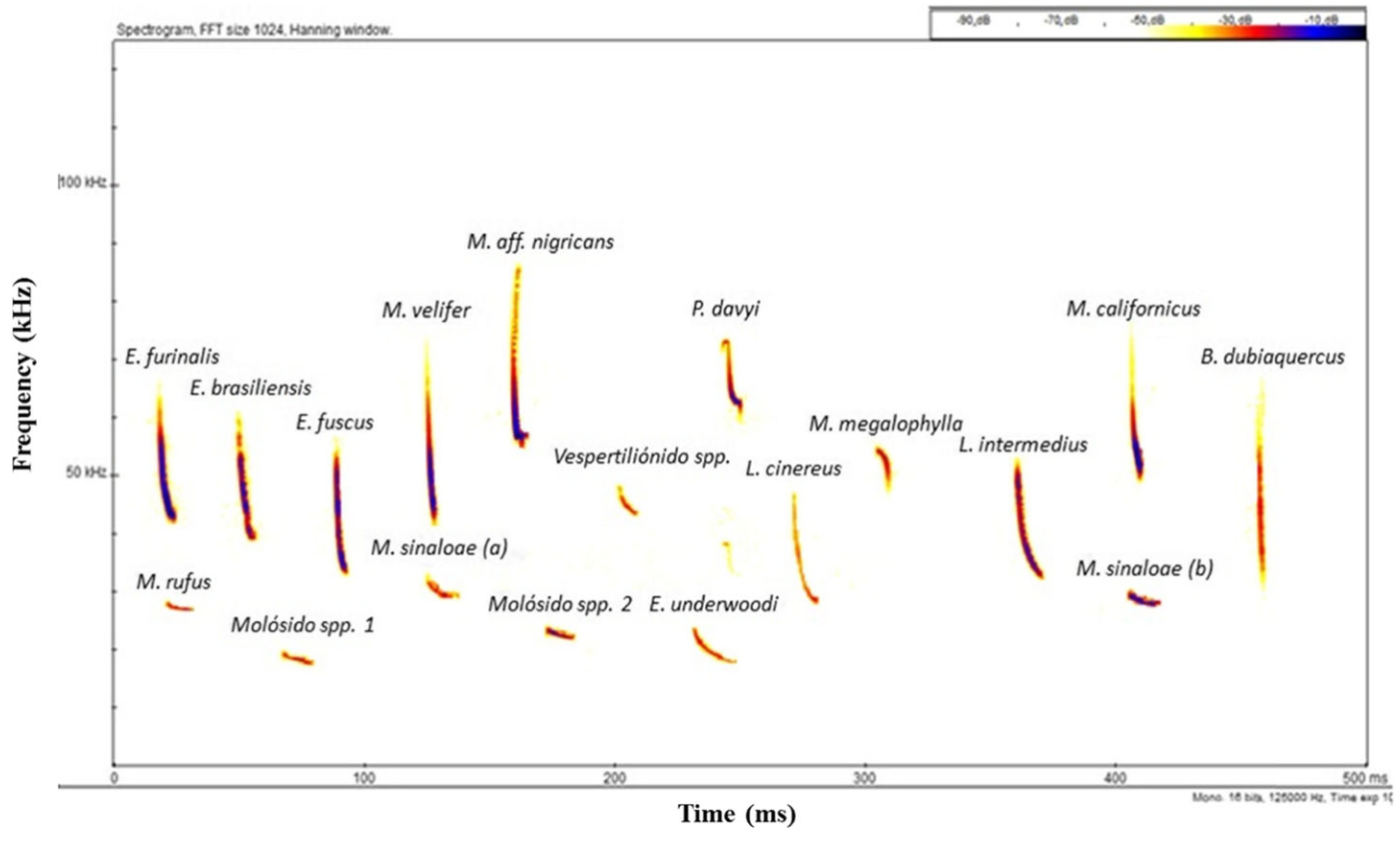
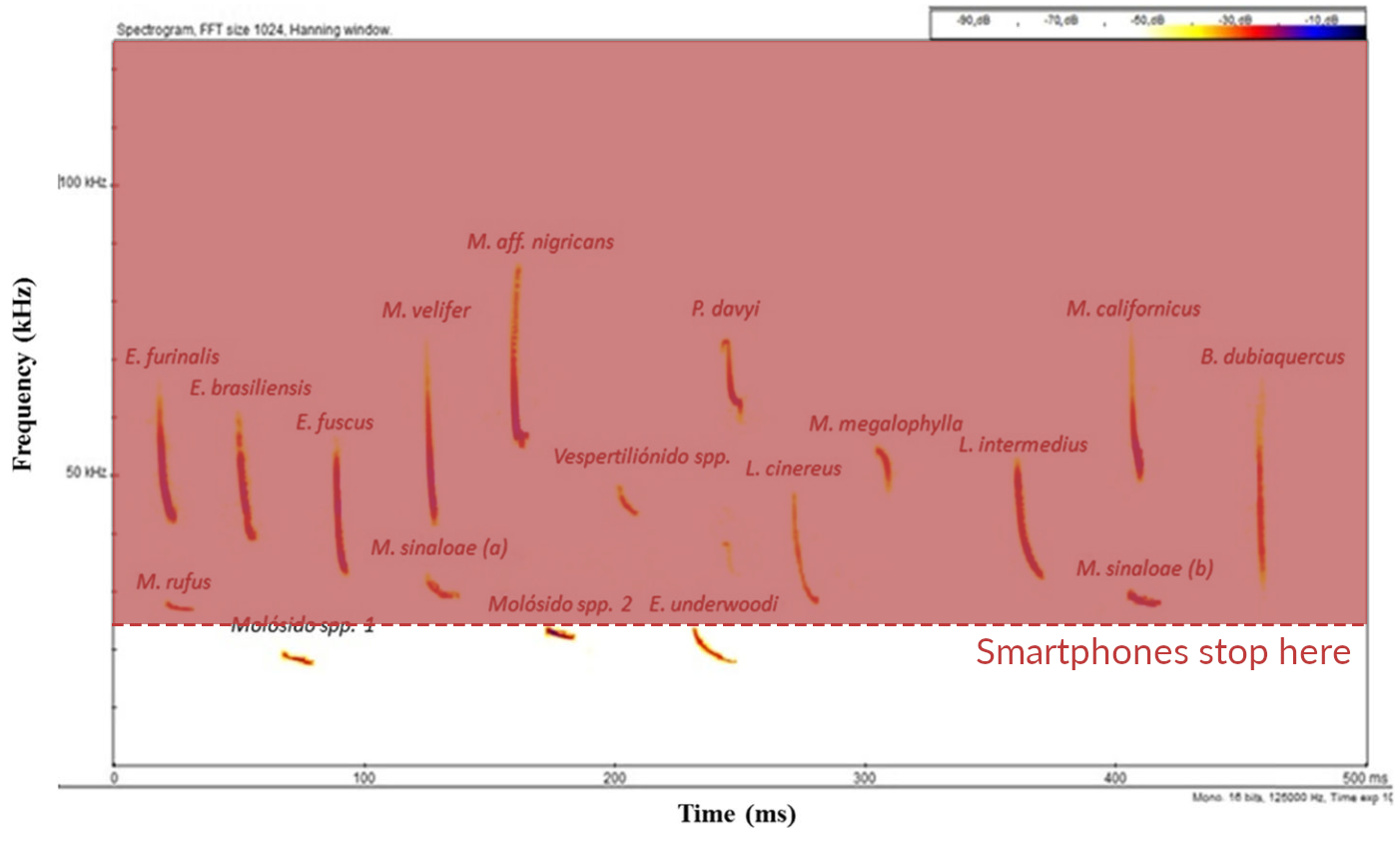
Bioacoustic signal occur over a very wide frequency range, and you need all of them
Rodríguez-Aguilar, G., et al. (2017) Urban Ecosystems, 20(2), 477–488
animal2vec 2.0
Decoupling the input shape from the output shape

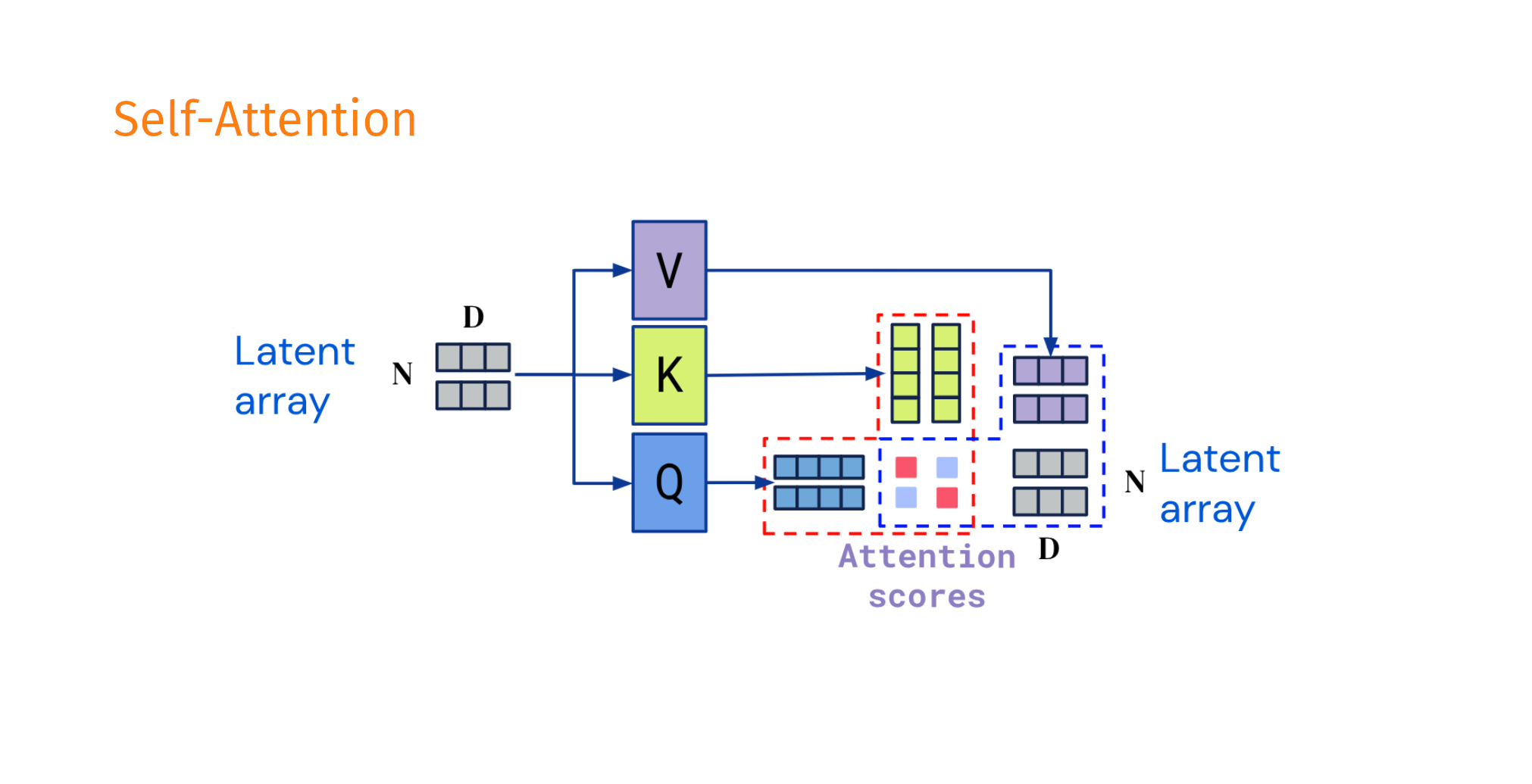
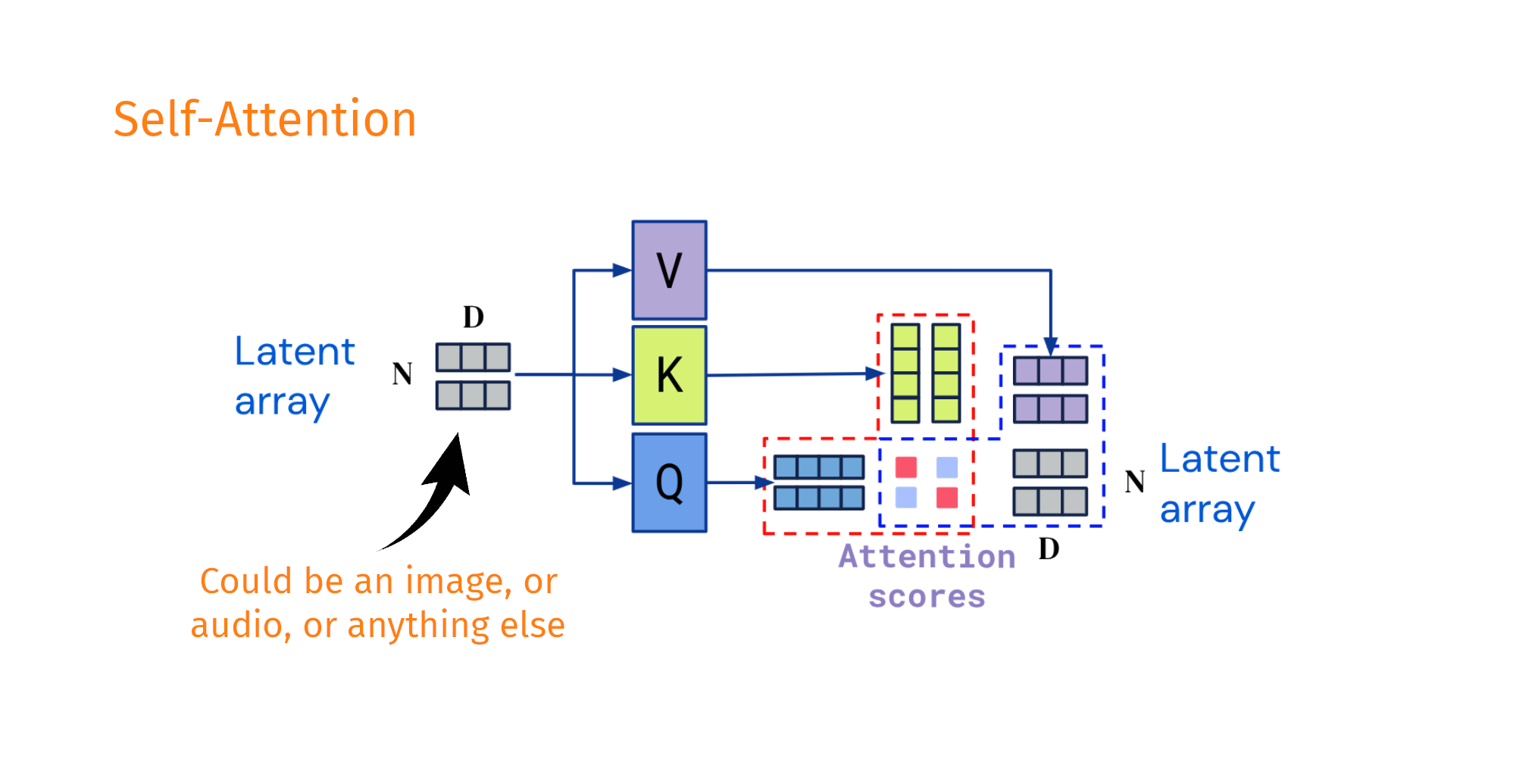
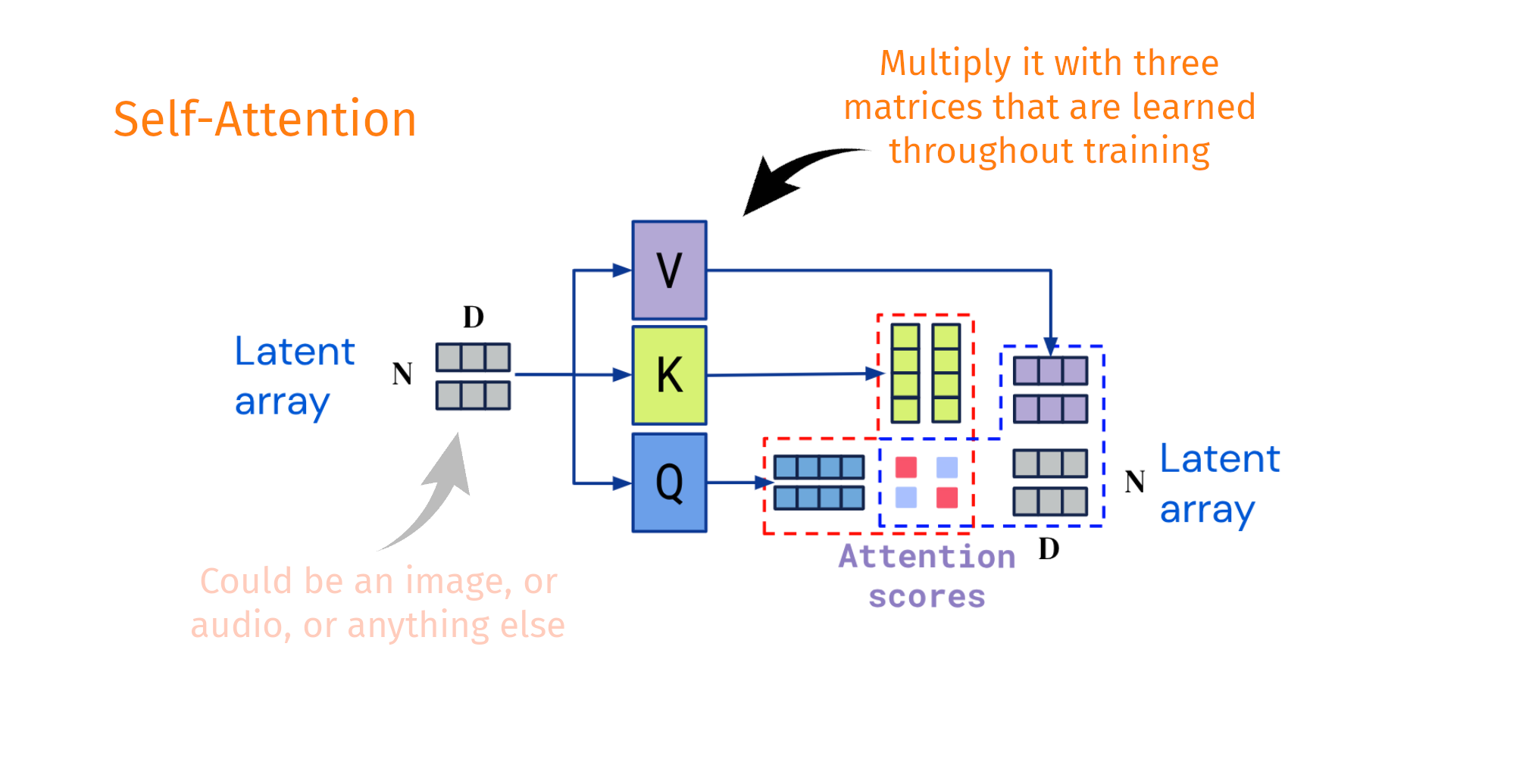
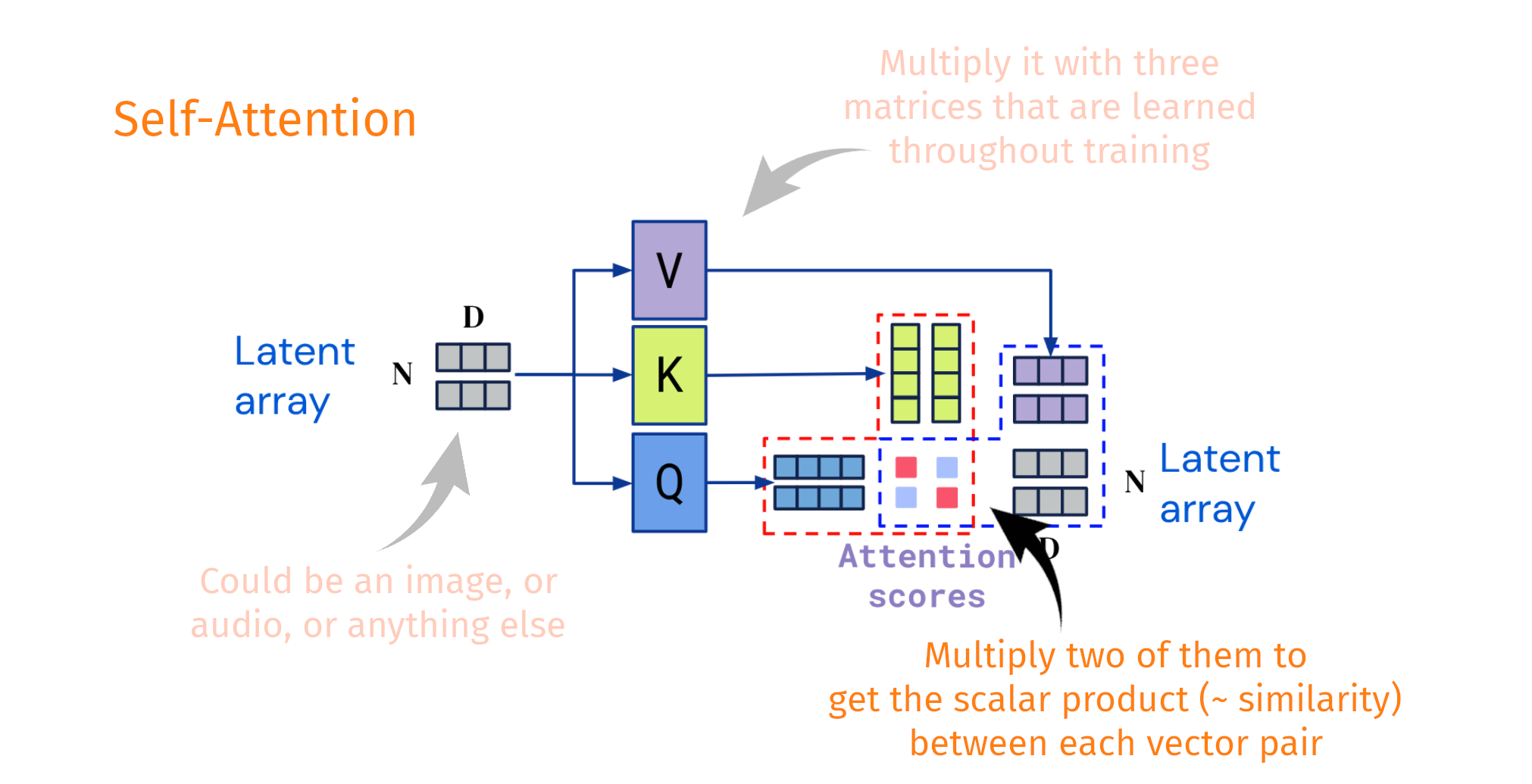
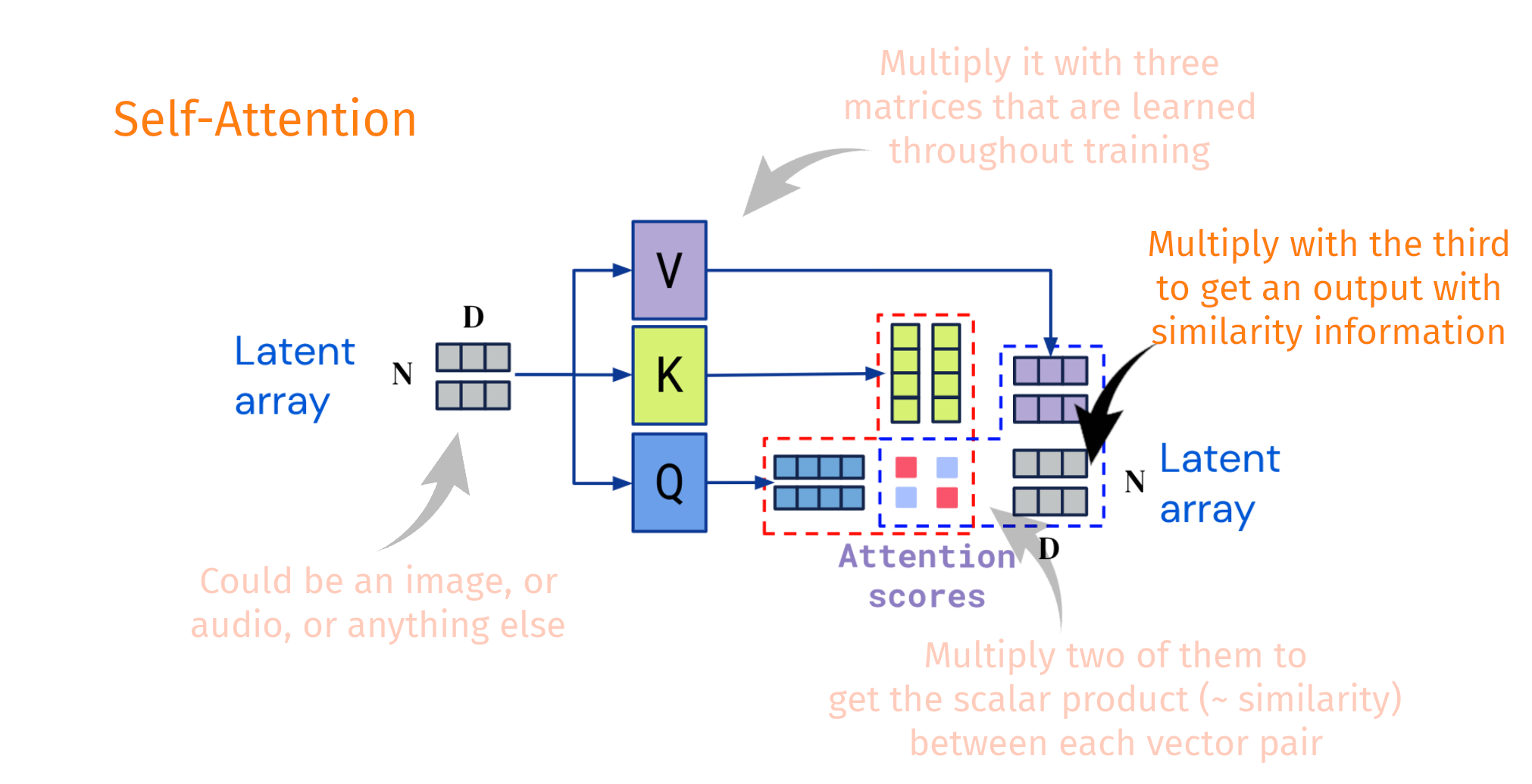
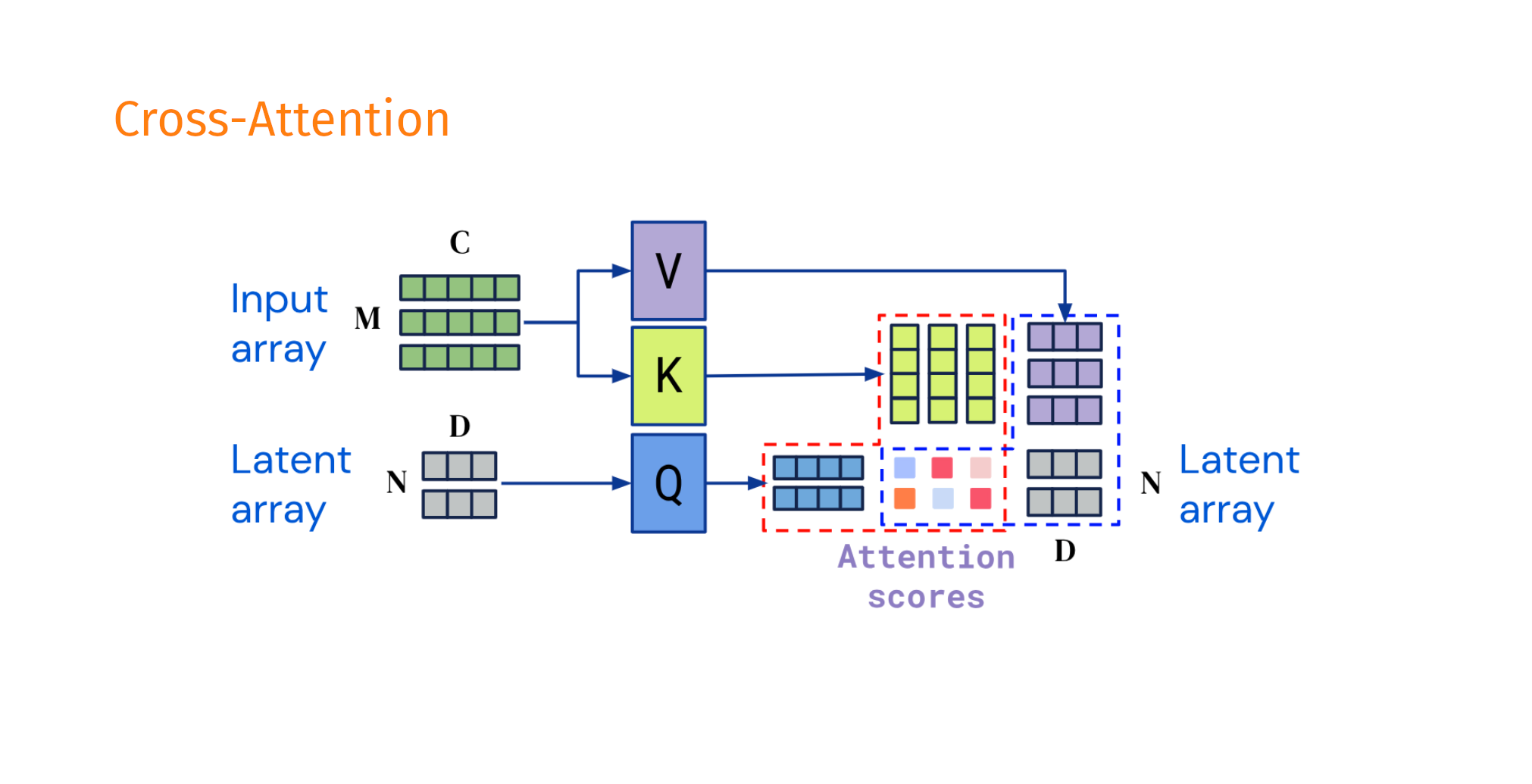
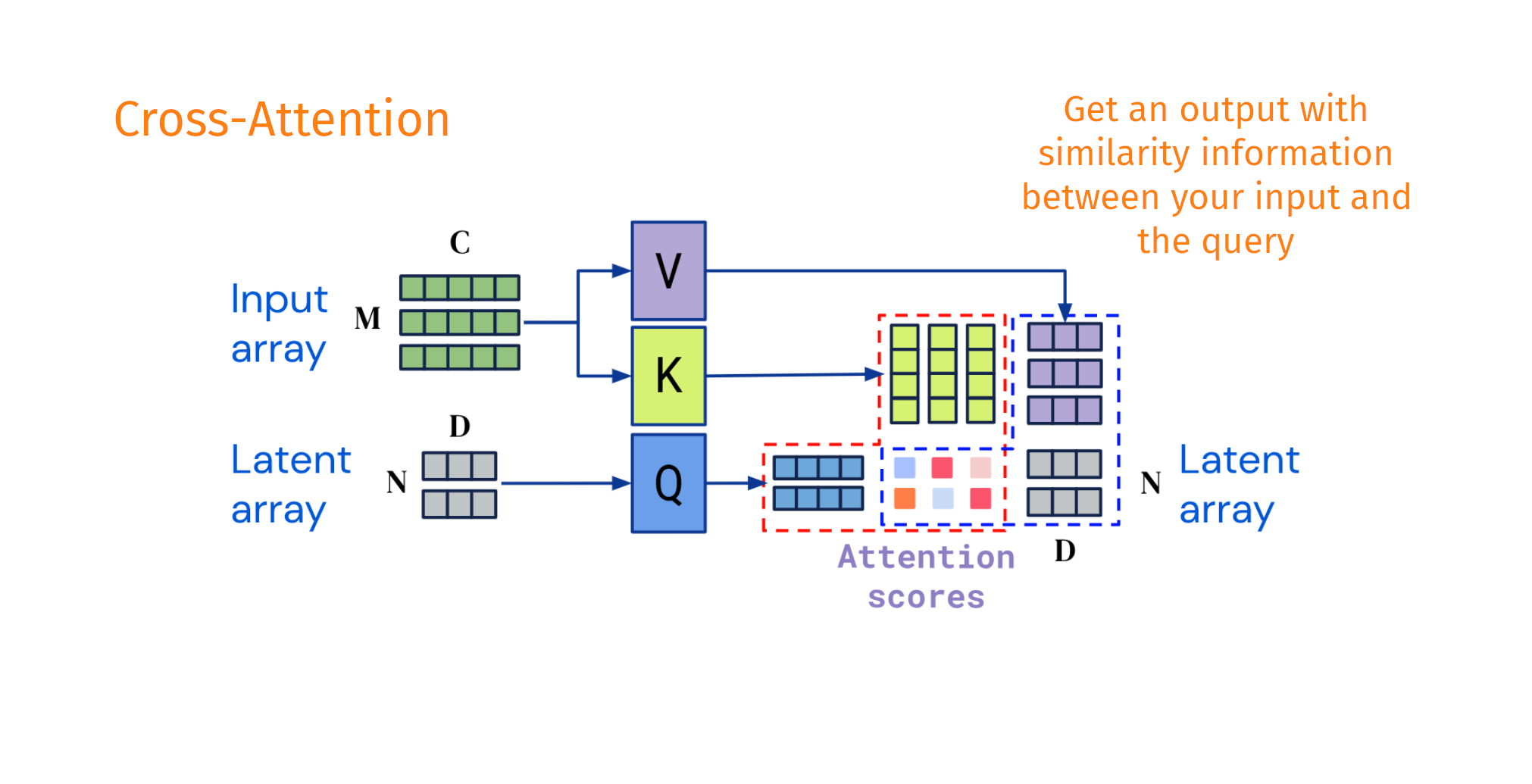

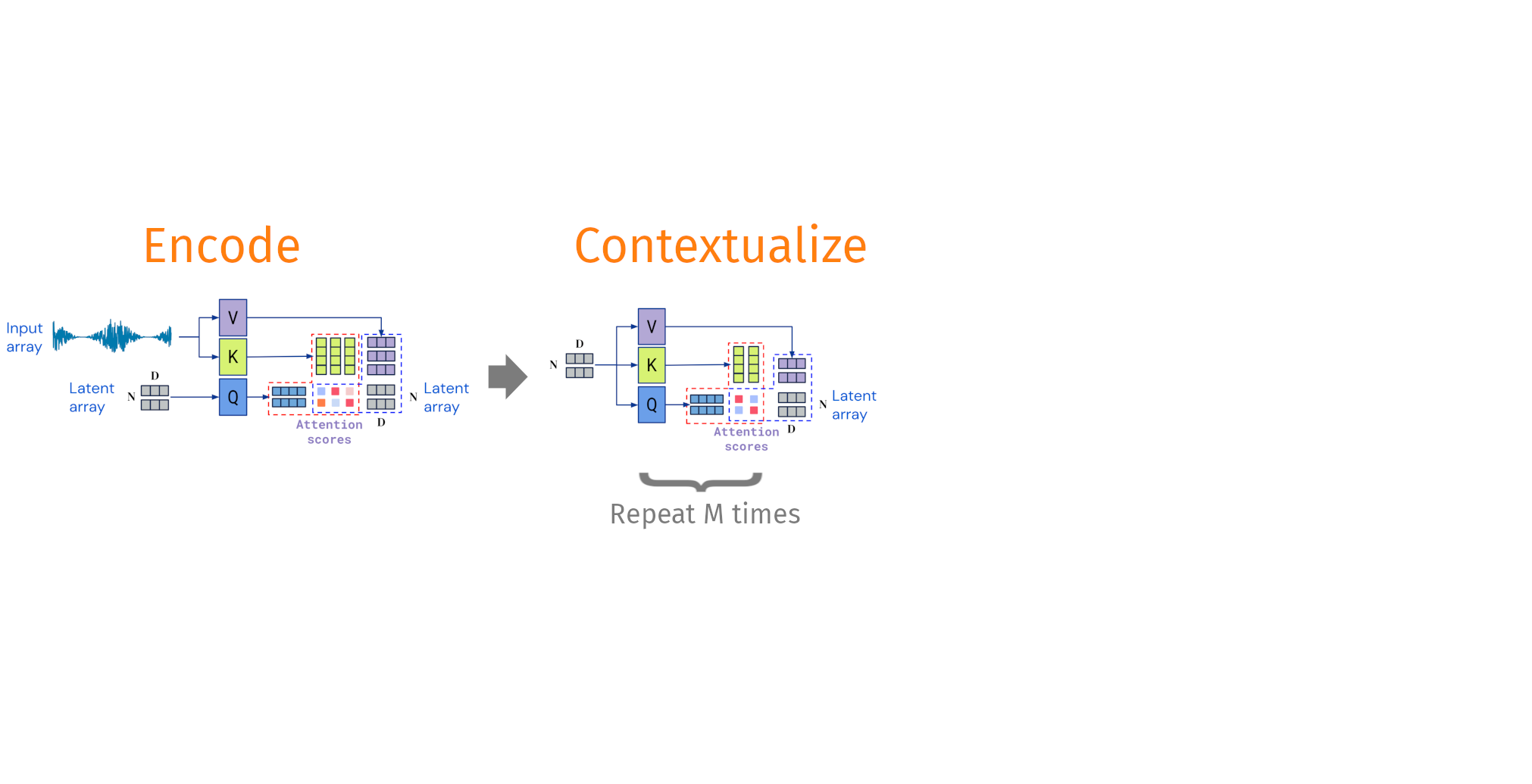
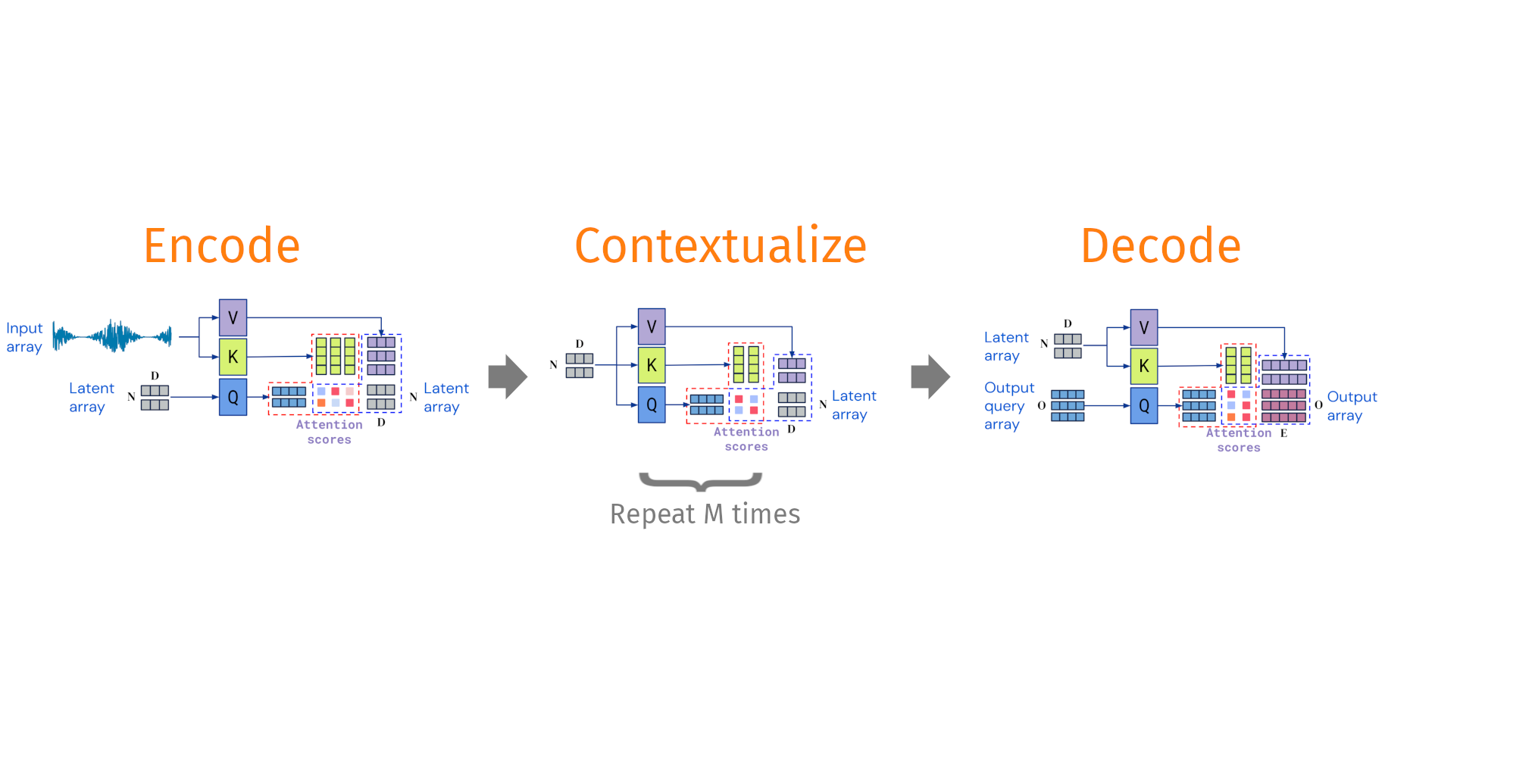
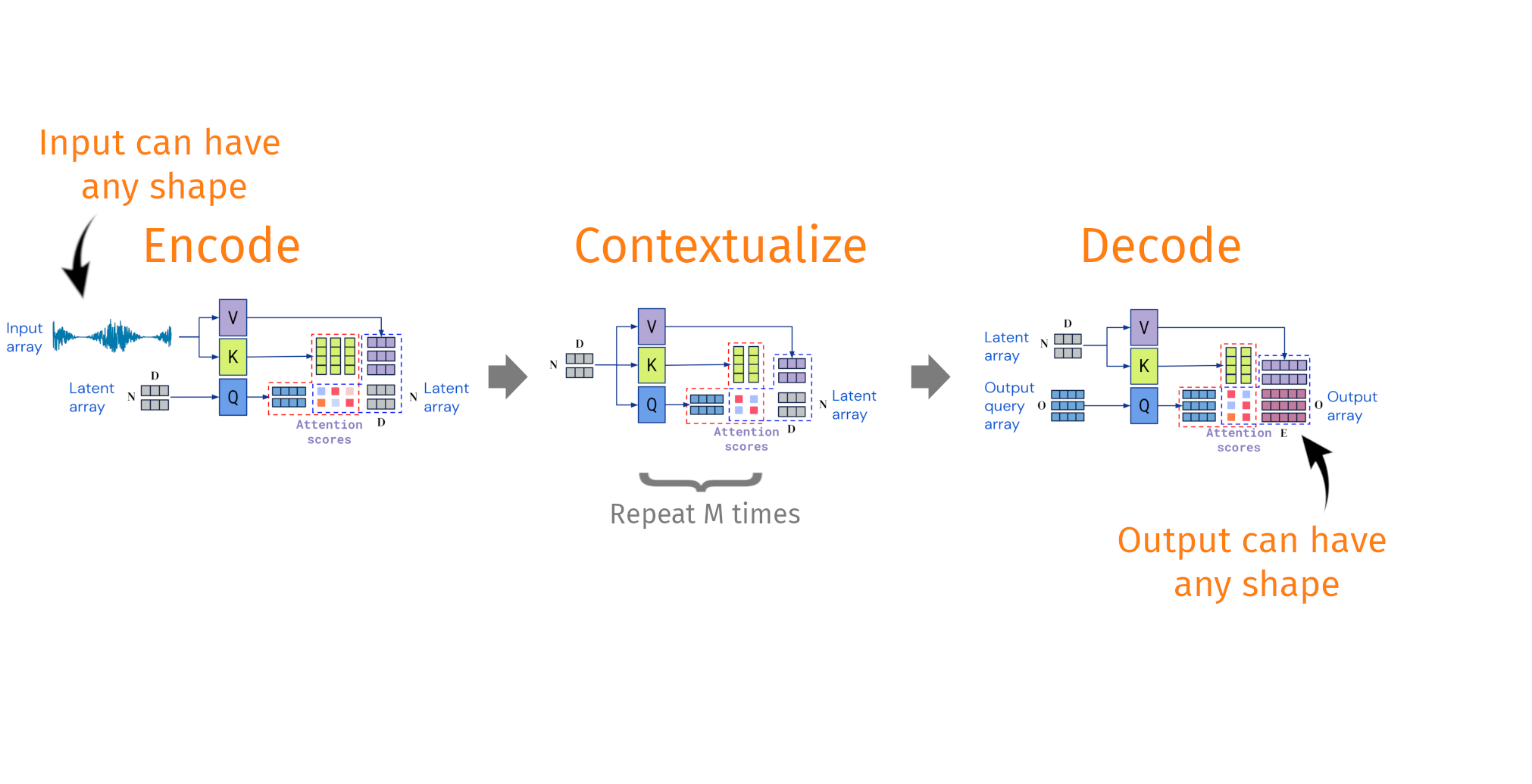
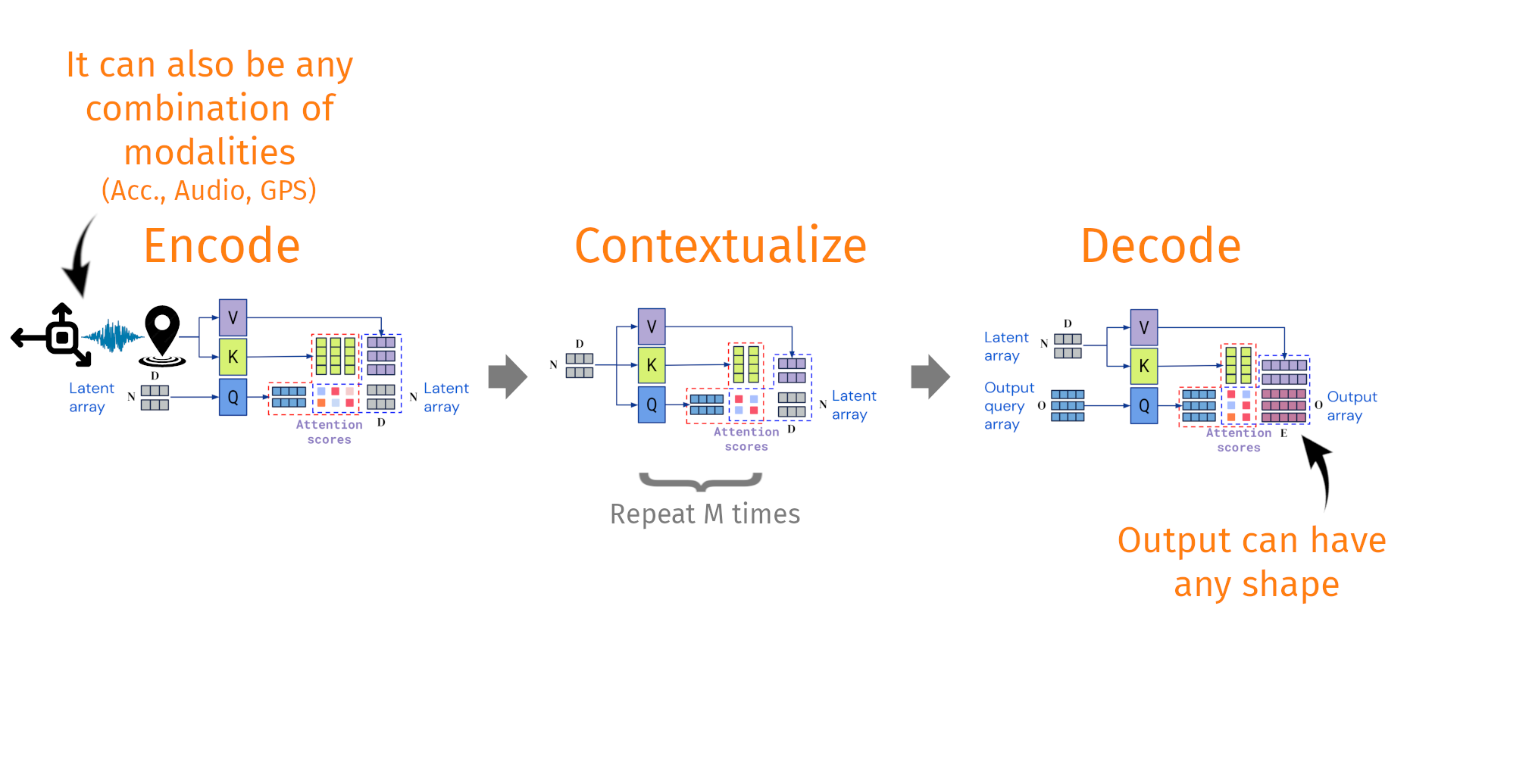
Taken and modified from Jaegle, A. et al. Perceiver IO arxiv:abs/2107.14795
Status and roadmap for animal2vec 2.0
- Codewise: Full rewrite of the codebase is at 95%
- It already brings huge improvements for train and inference speed
- Pretraining time on MeerKAT is 5 - 6 times faster → days instead of weeks
- Will include the sample-rate dependent positional encoding approach (Marius' project)
- The new codebase runs natively on multiple nodes, each having multiple GPUs using either Kubernetes deployment (like with our CCU cluster) or a Slurm Workload Manager (like the system at MPCDF)
- Datawise: We already have a very large amount of bioacoustic data
- Everything from Xeno-Canto, iNaturalist, Tierstimmenarchiv (1.3M files -> 13k hours)
- This covers 96% of all known bird-species
- A large subset of Googles Audioset dataset (600 hours)
- Animal and Environmental sounds, plus various misc. stuff (noise, soundscapes, motor sounds, ...)
- 10-15k hours of marine data (Sanctuary Soundscape Monitoring Project (SanctSound), The William A. Watkins Collection, The Orchive, ...)
- We still have to take stock how much MPIAB data we use, but the expected order is ~10k hours
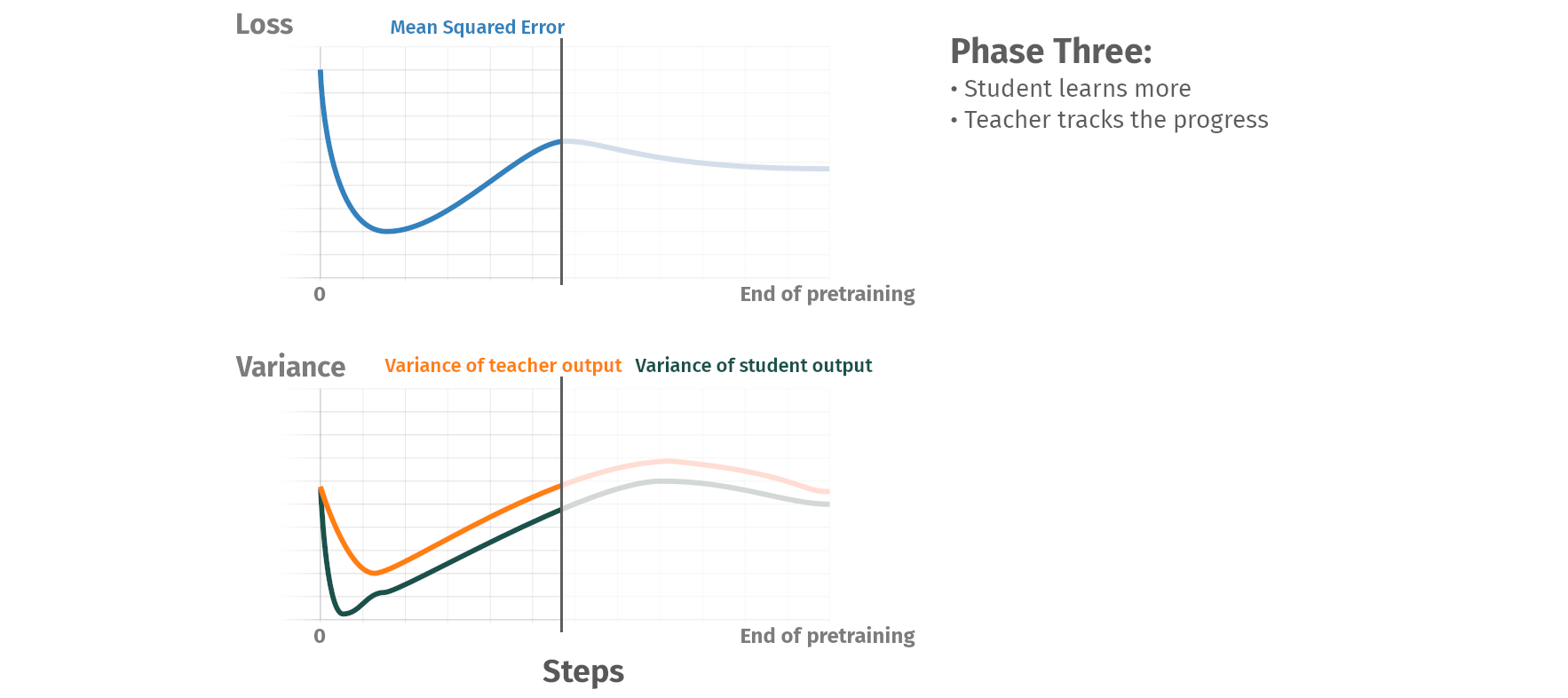
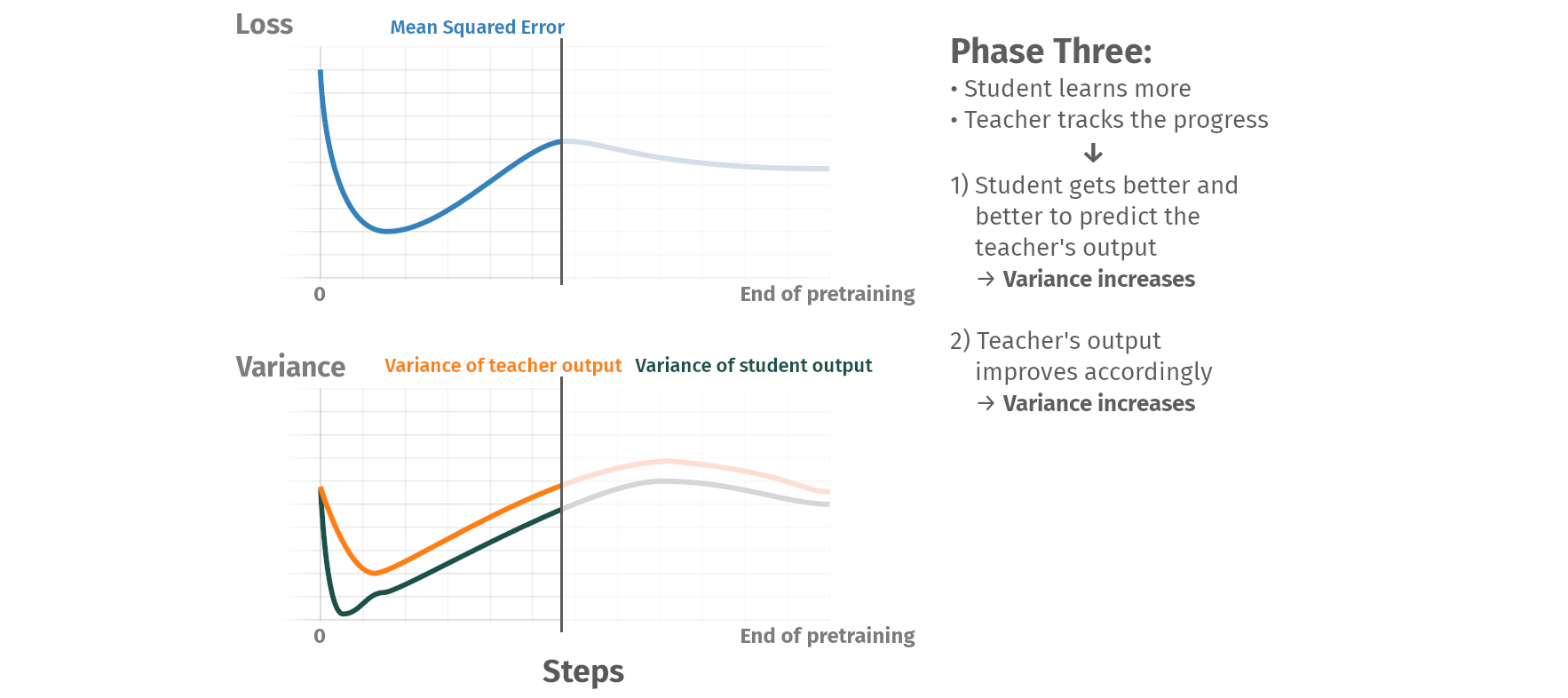
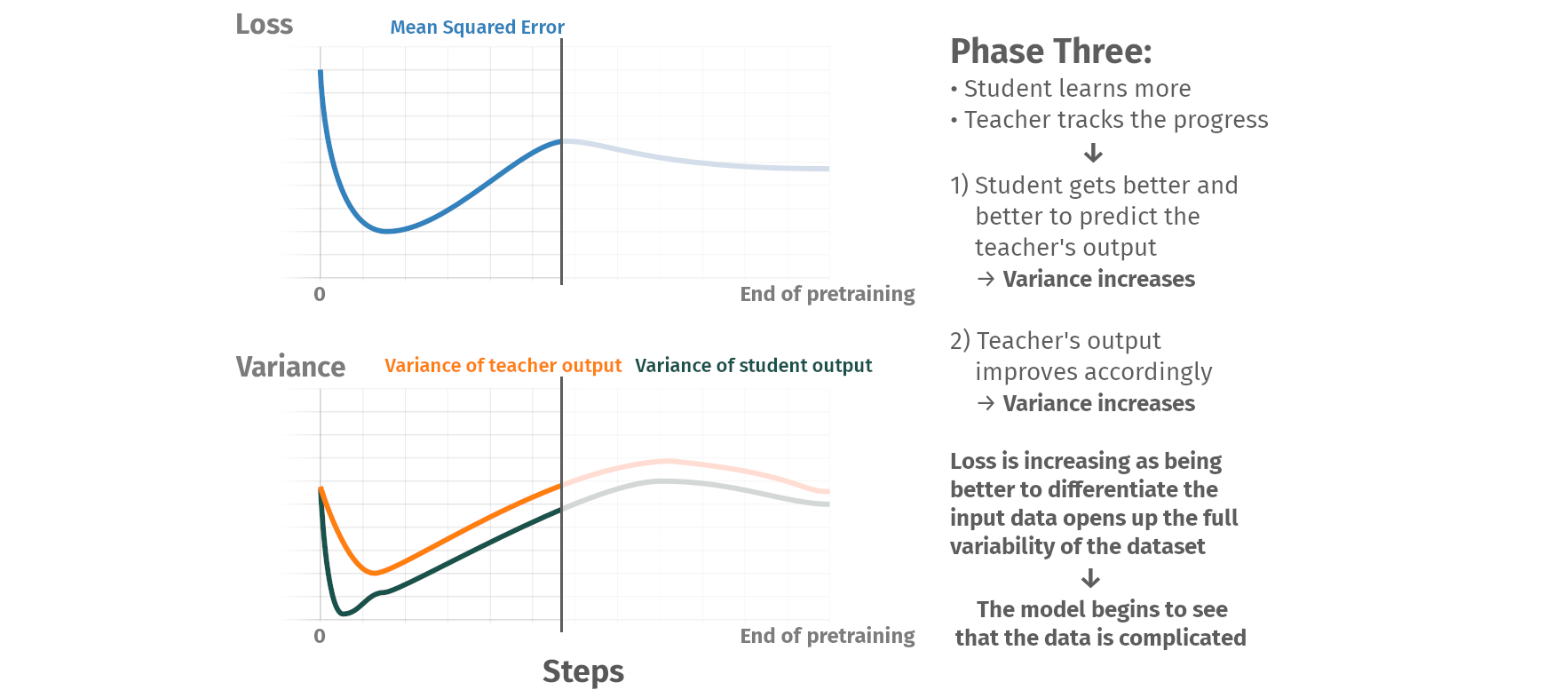
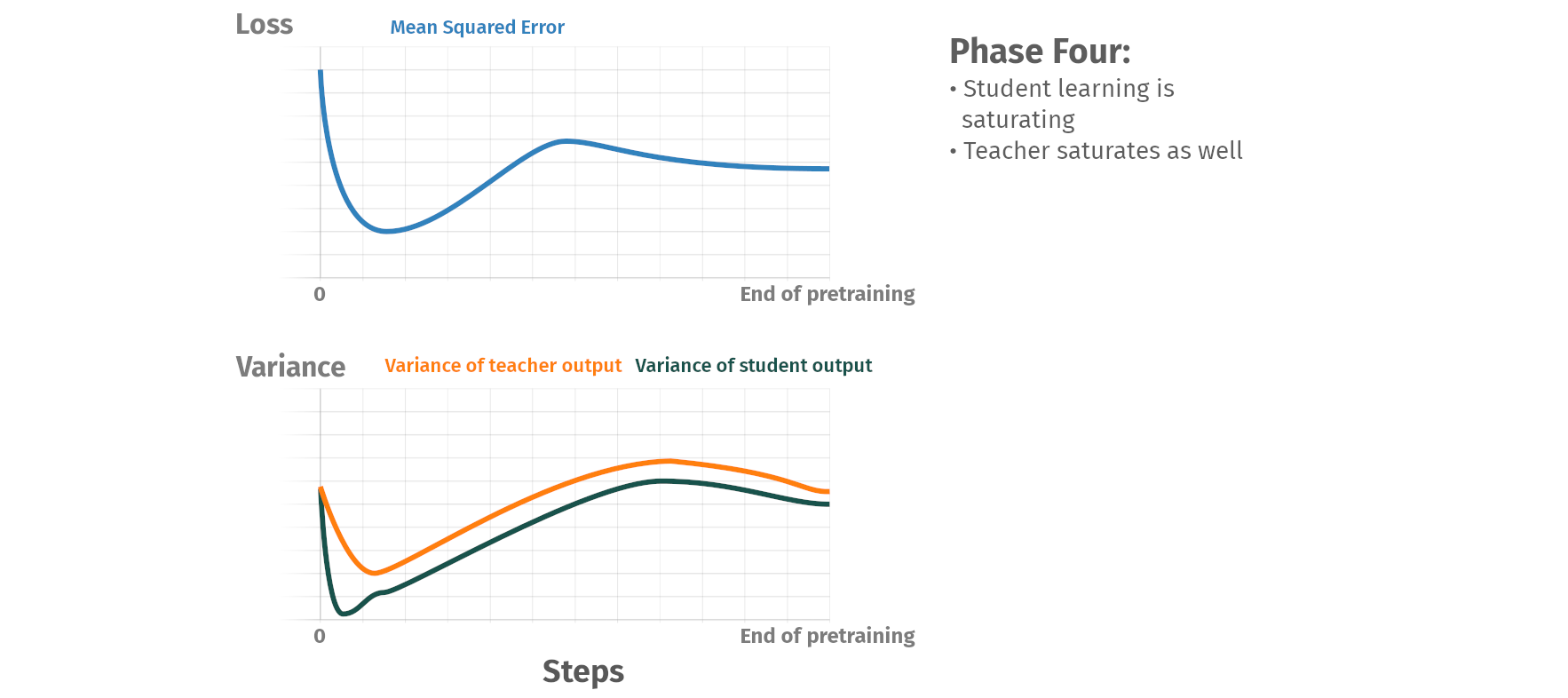
Pretraining phases
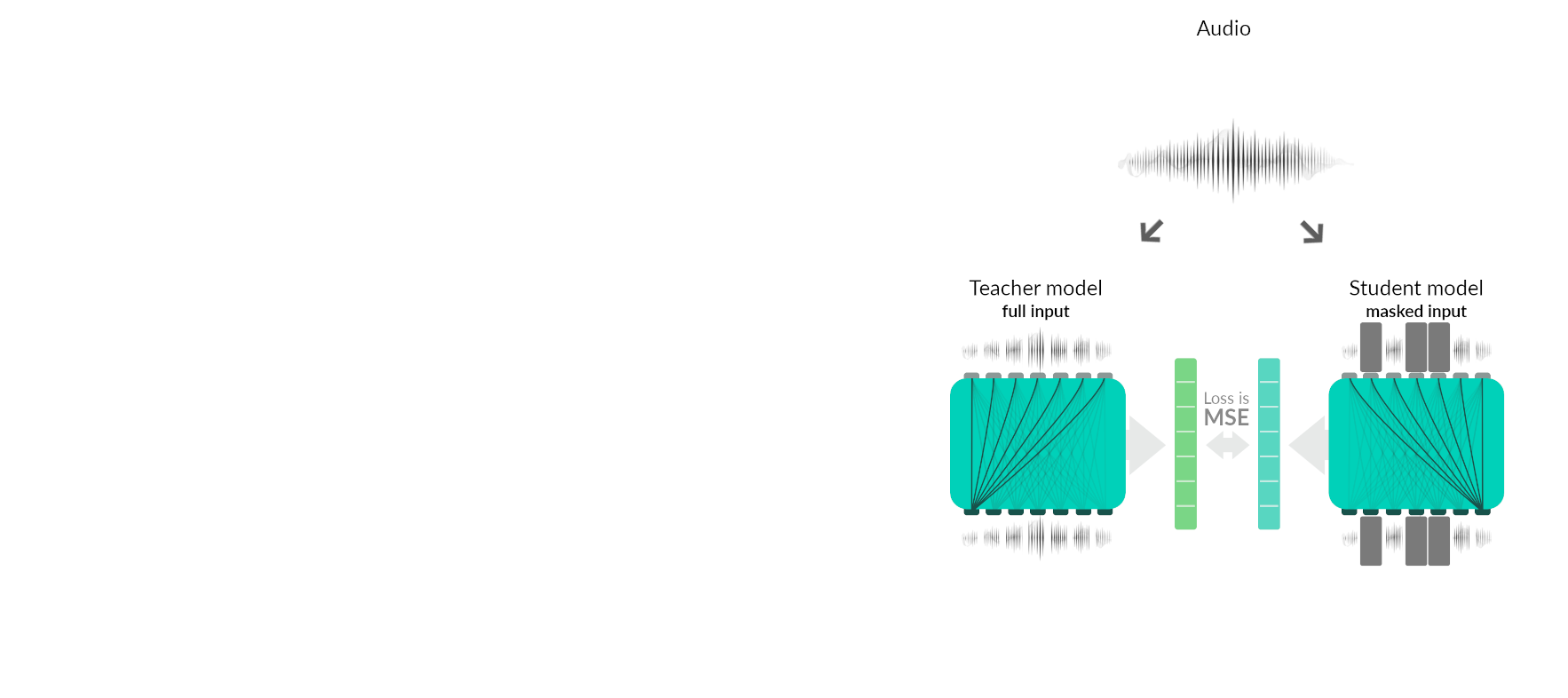
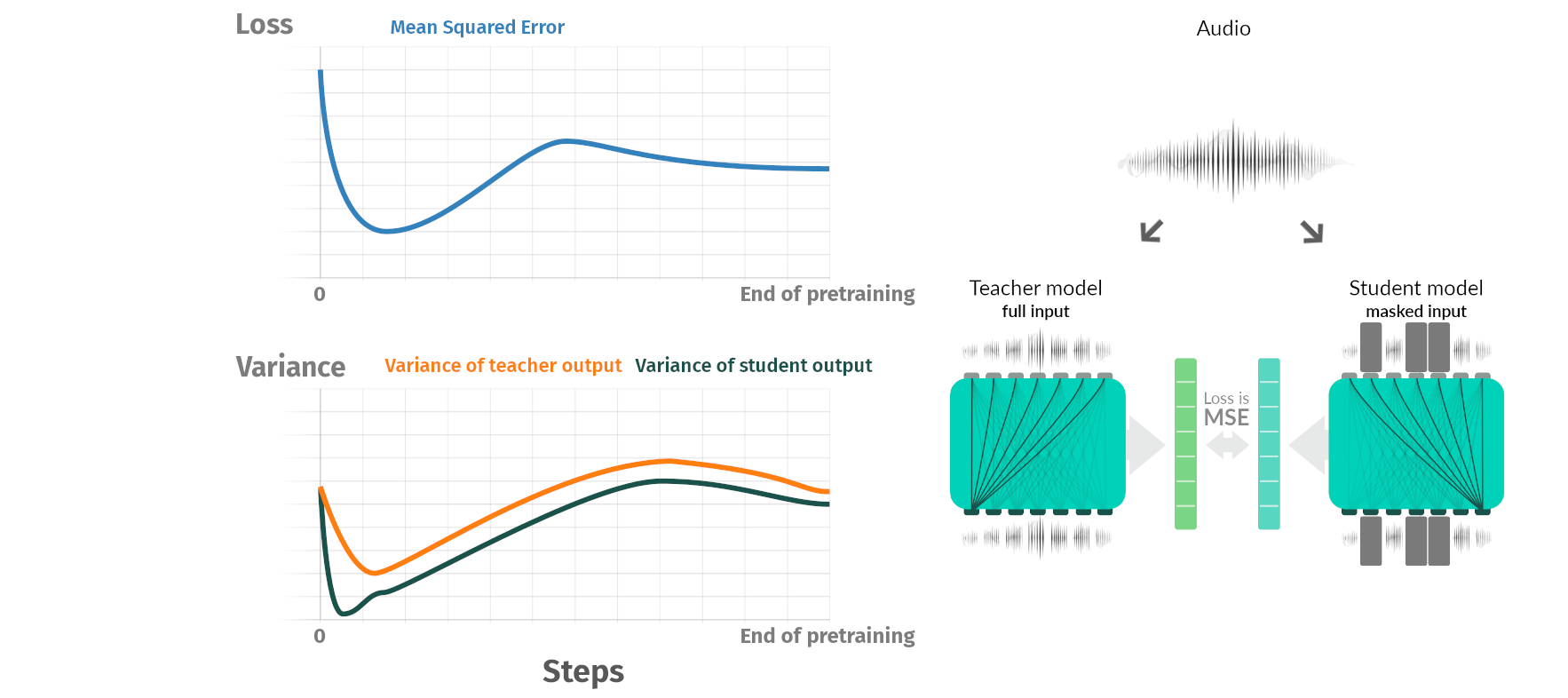
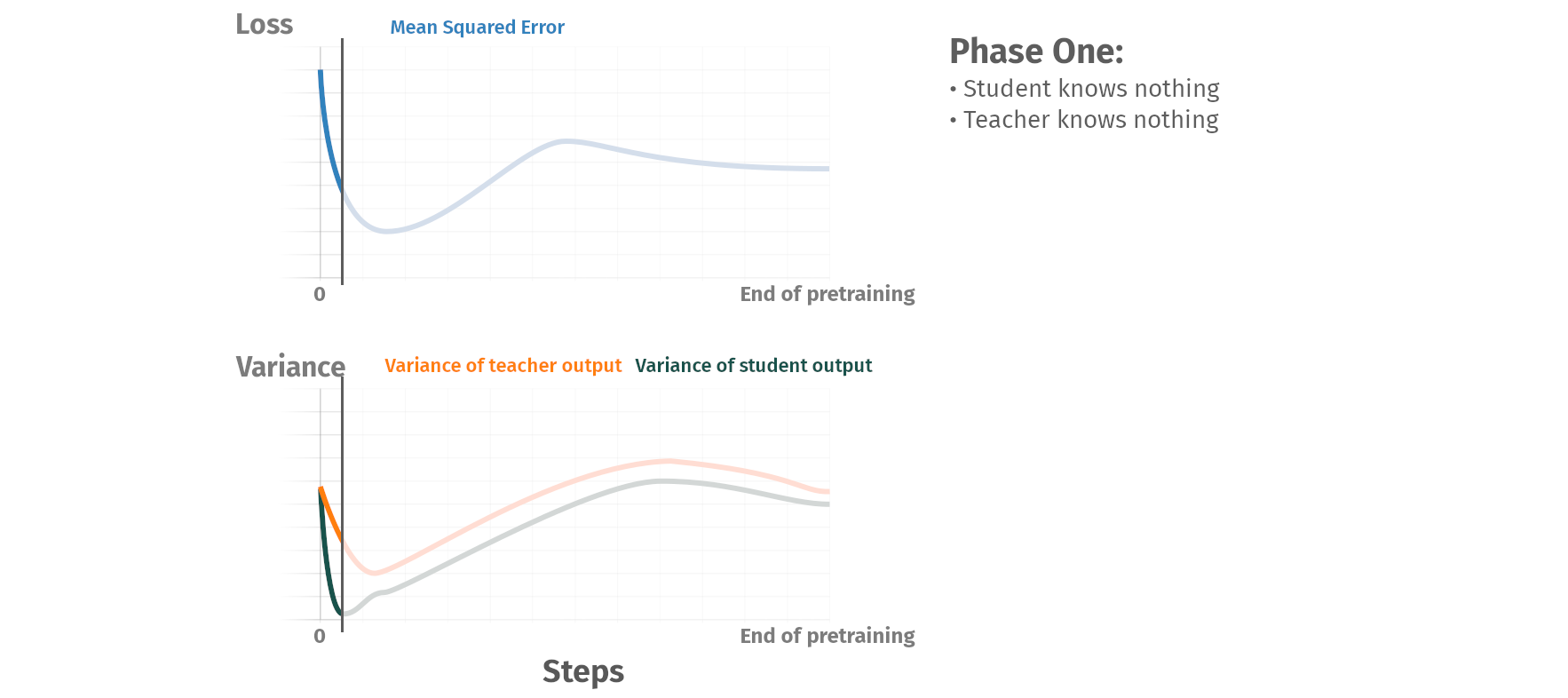
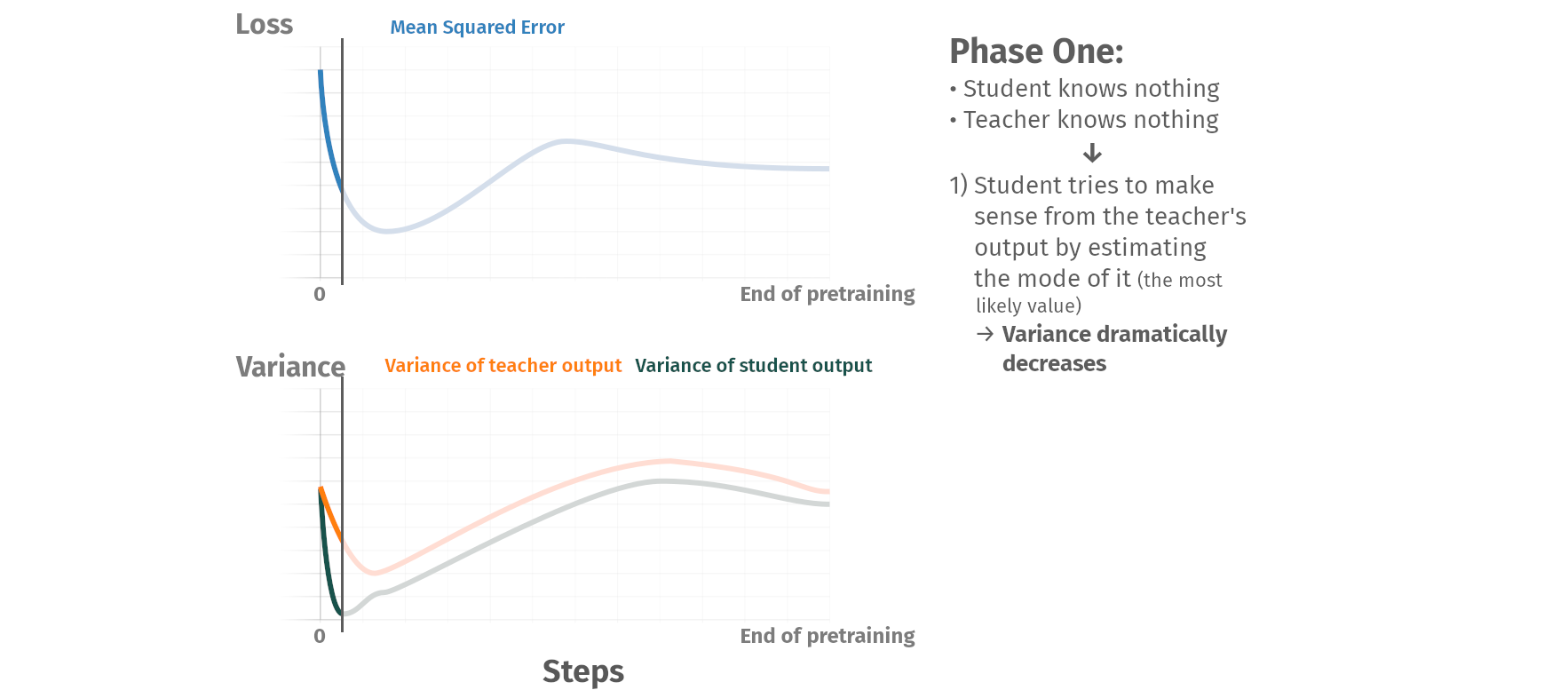
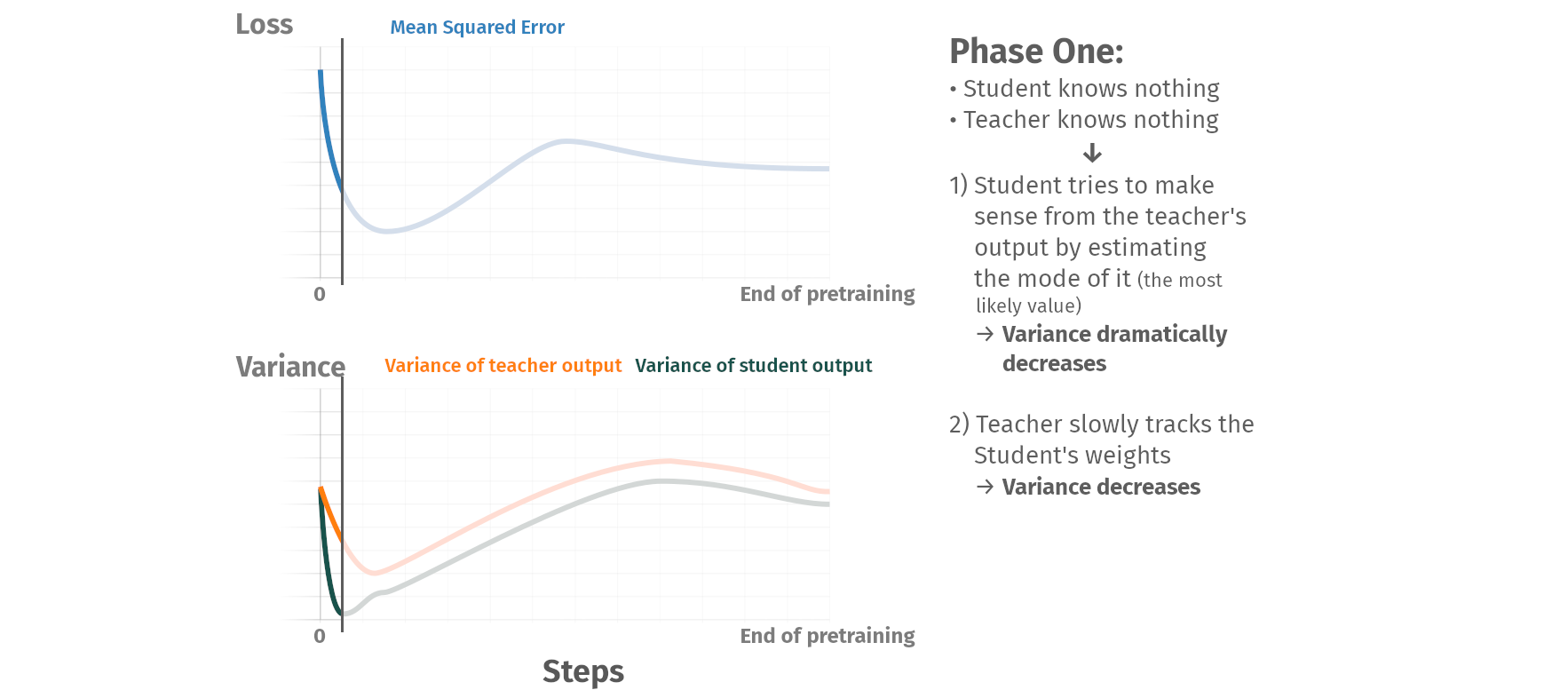
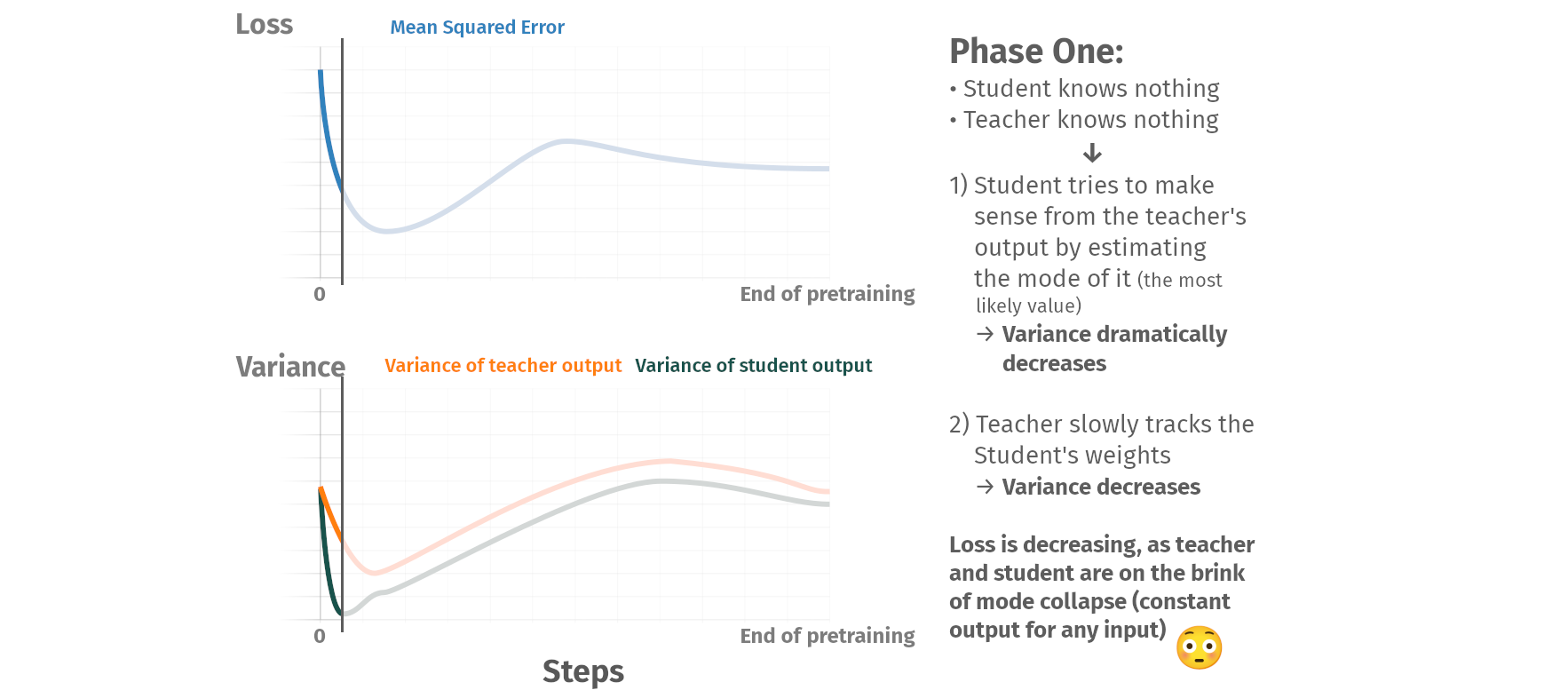
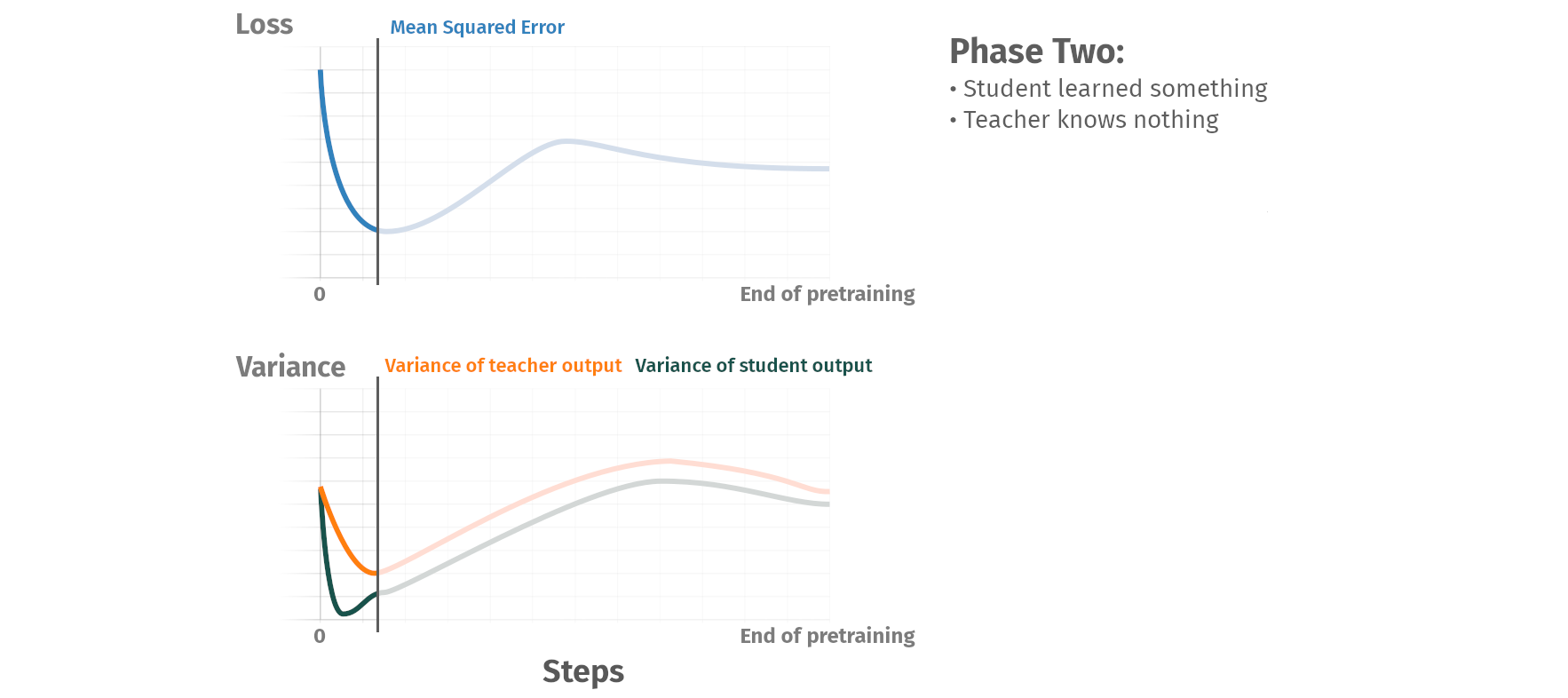
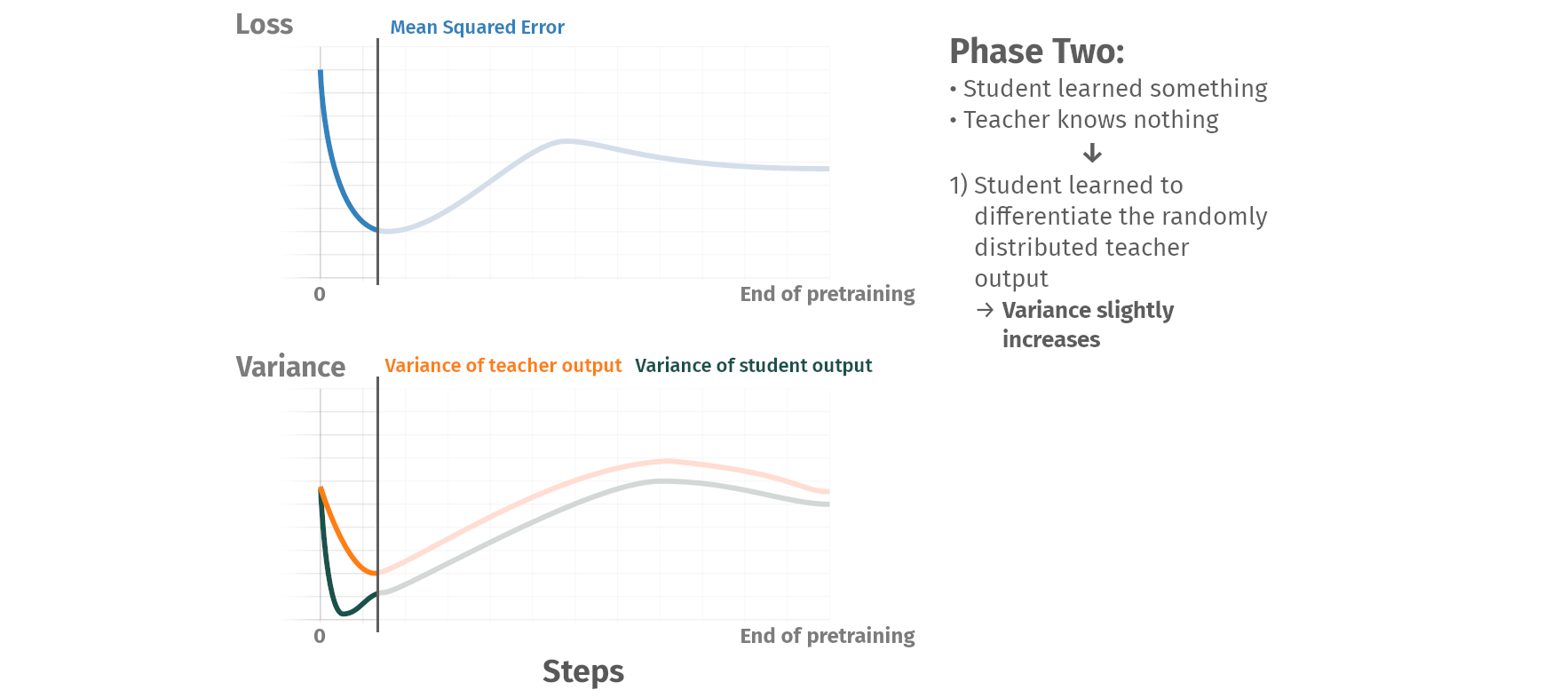
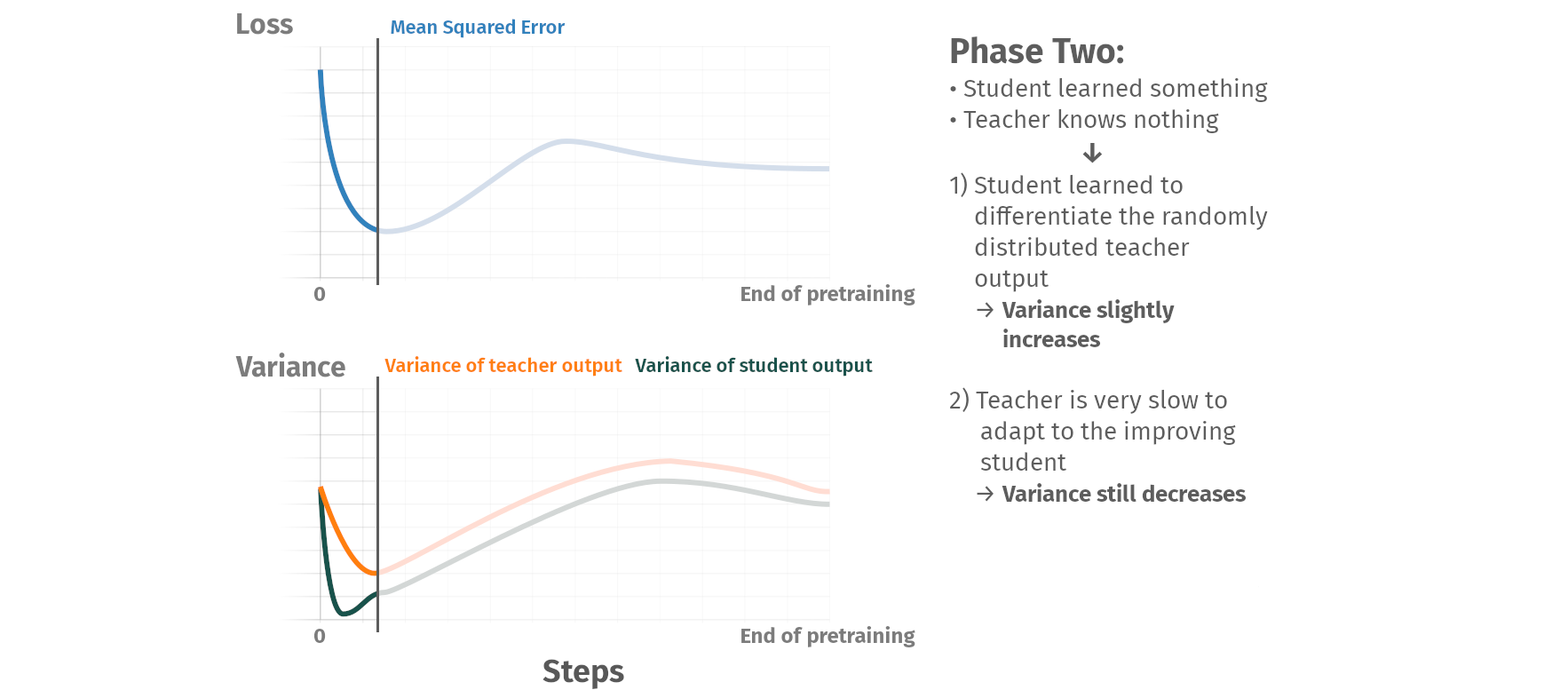
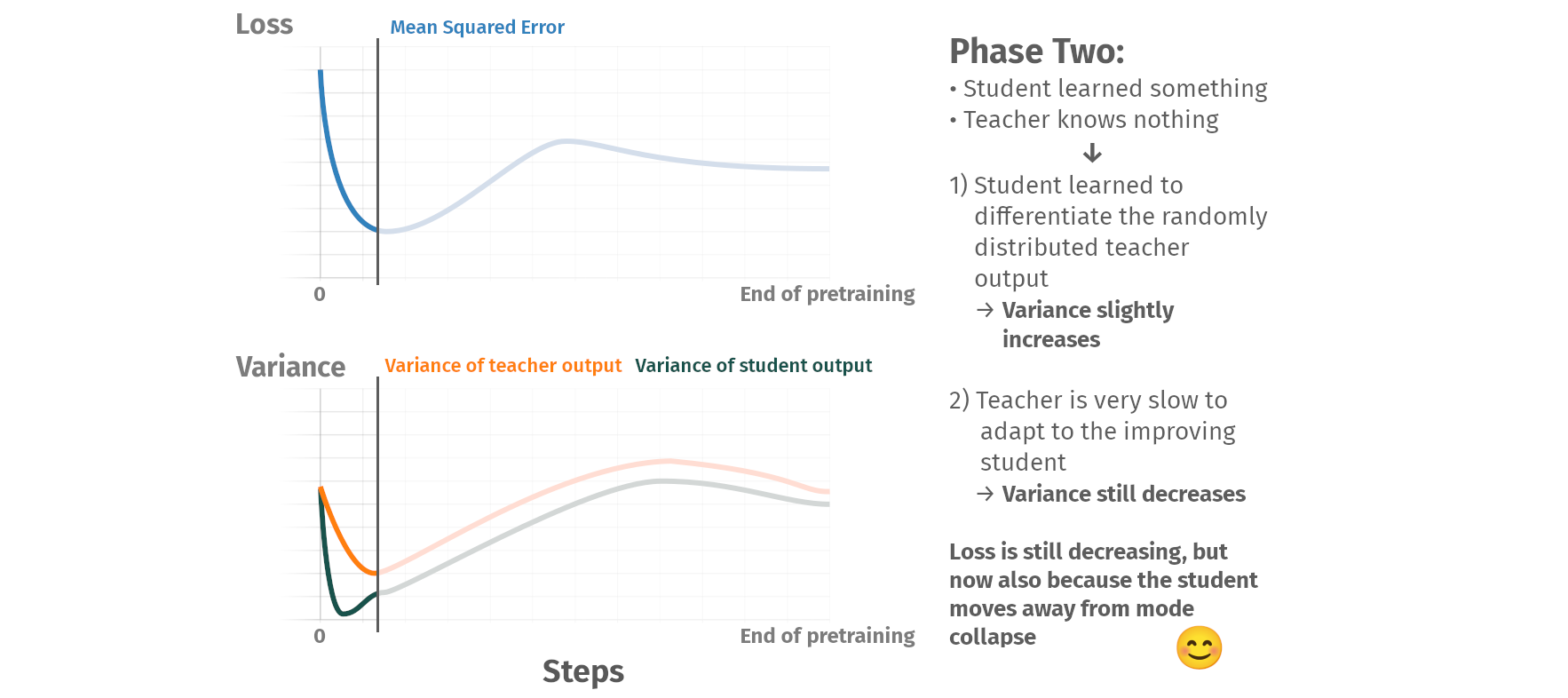
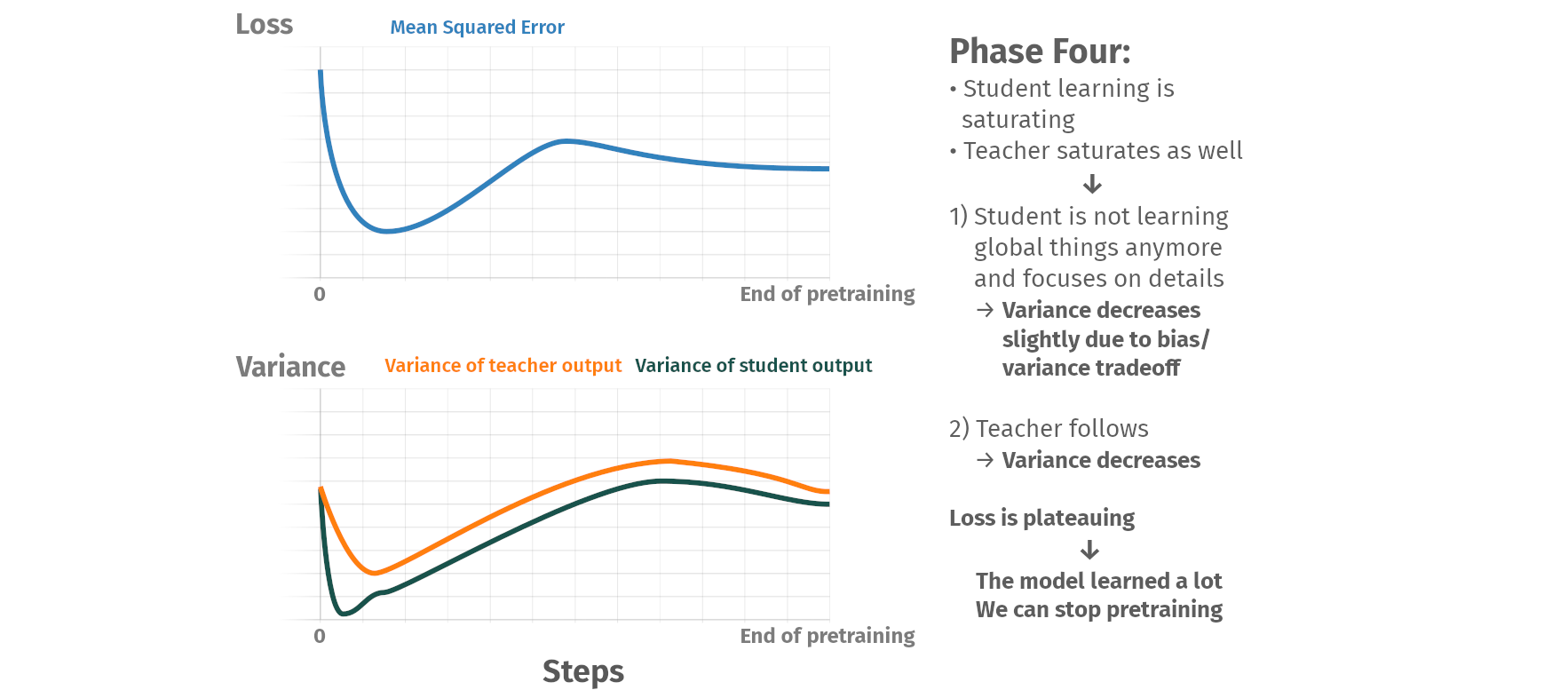
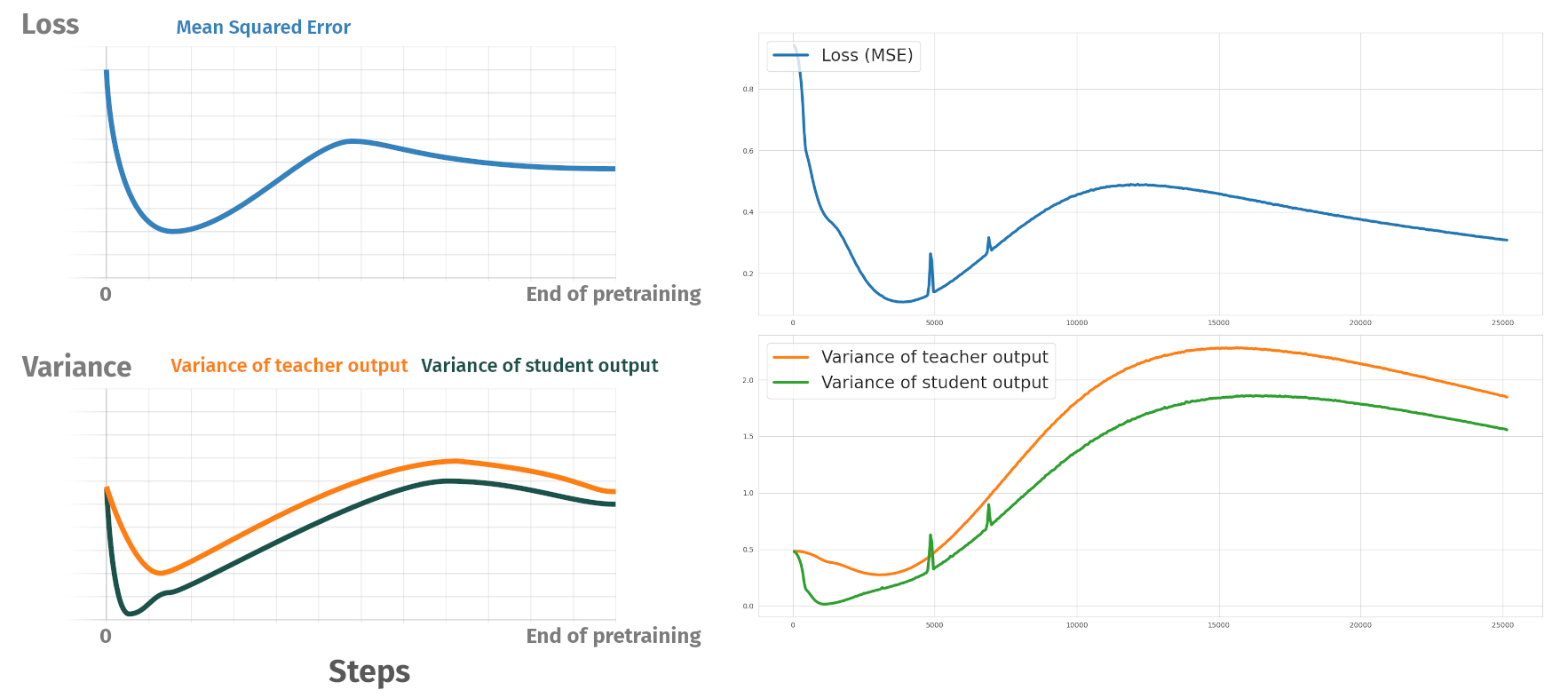
Summary
- We now have predictions for all CCAS species, and we are still working towards making them even better
- Meerkats: Current predictions are the best we can get with animal2vec 1.0
- Coati: Preliminary results are good. Predictions are the best we can get with animal2vec 1.0
- Hyena: Pretraining status is good. Finetuning results can be improved with more labels, but are good
- We have an idea on how to tackle the domain-specific challenges in bioacoustics to build the next generation of animal2vec
- New codebase: Almost ready and initial runs look promising
- Dataset aggregation: Expected timeline is one month until the data is ready
- Computational resources: Will be provided by the Max Planck Computing and Data Facility
Status and future plans
animal2vec
A deep learning based framework for large scale bioacoustic tasks
Max Planck Institute of Animal Behavior
Department for the Ecology of Animal Societies
Communication and Collective Movement (CoCoMo) Group