Status and future plans
animal2vec
Max Planck Institute of Animal Behavior
Department for the Ecology of Animal Societies
Communication and Collective Movement (CoCoMo) Group

Super-fast recap
The concepts
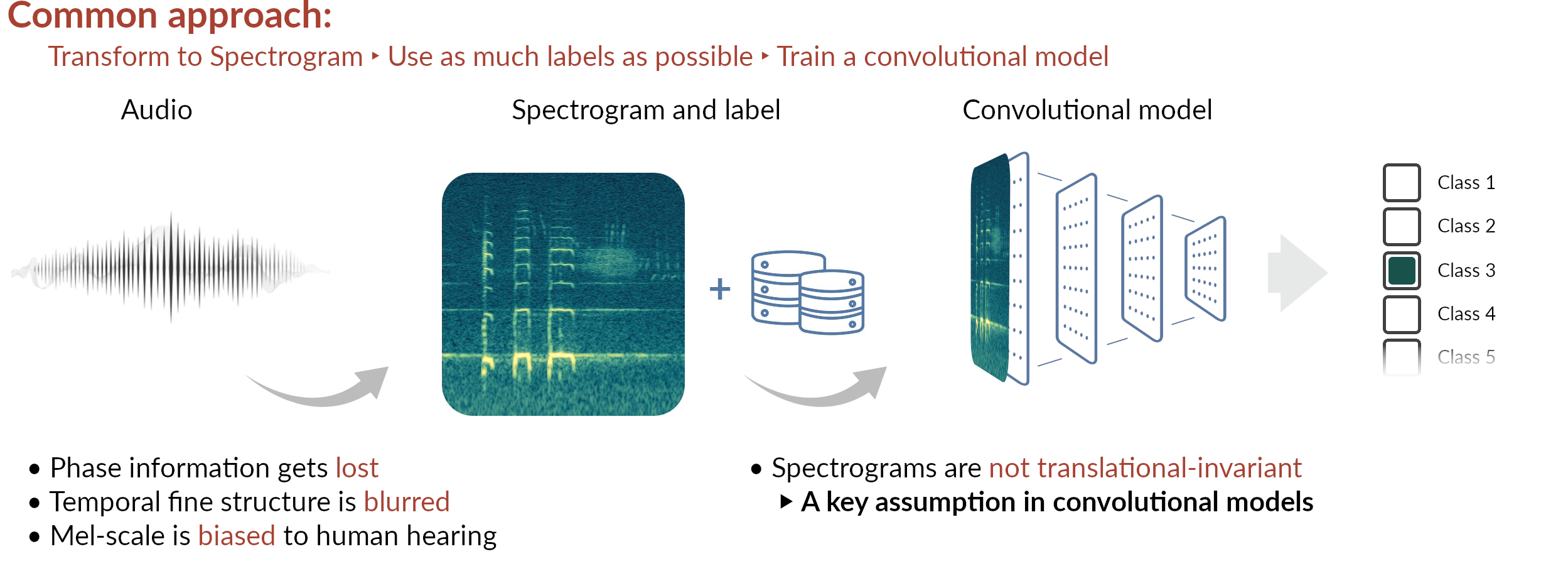
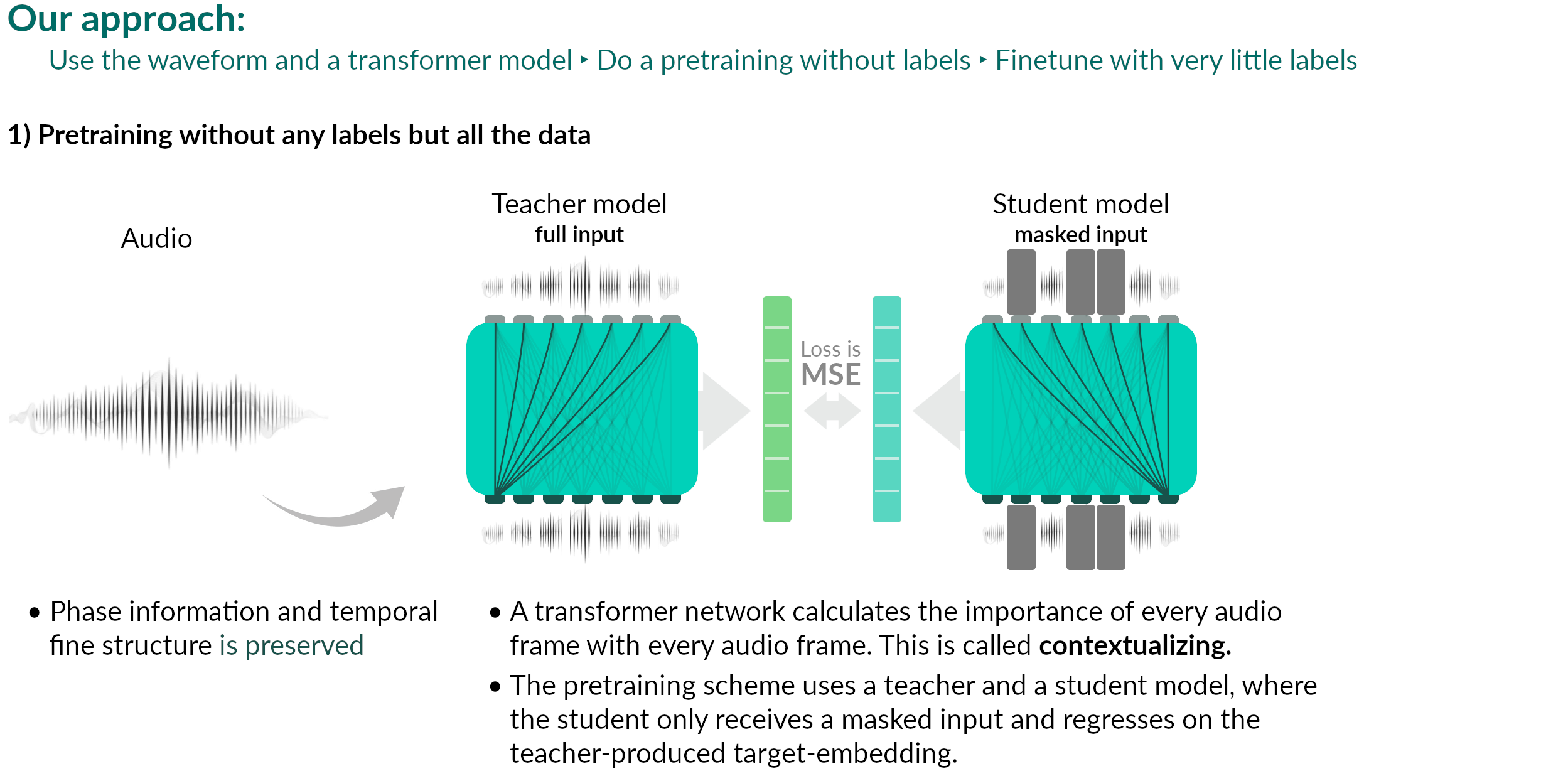
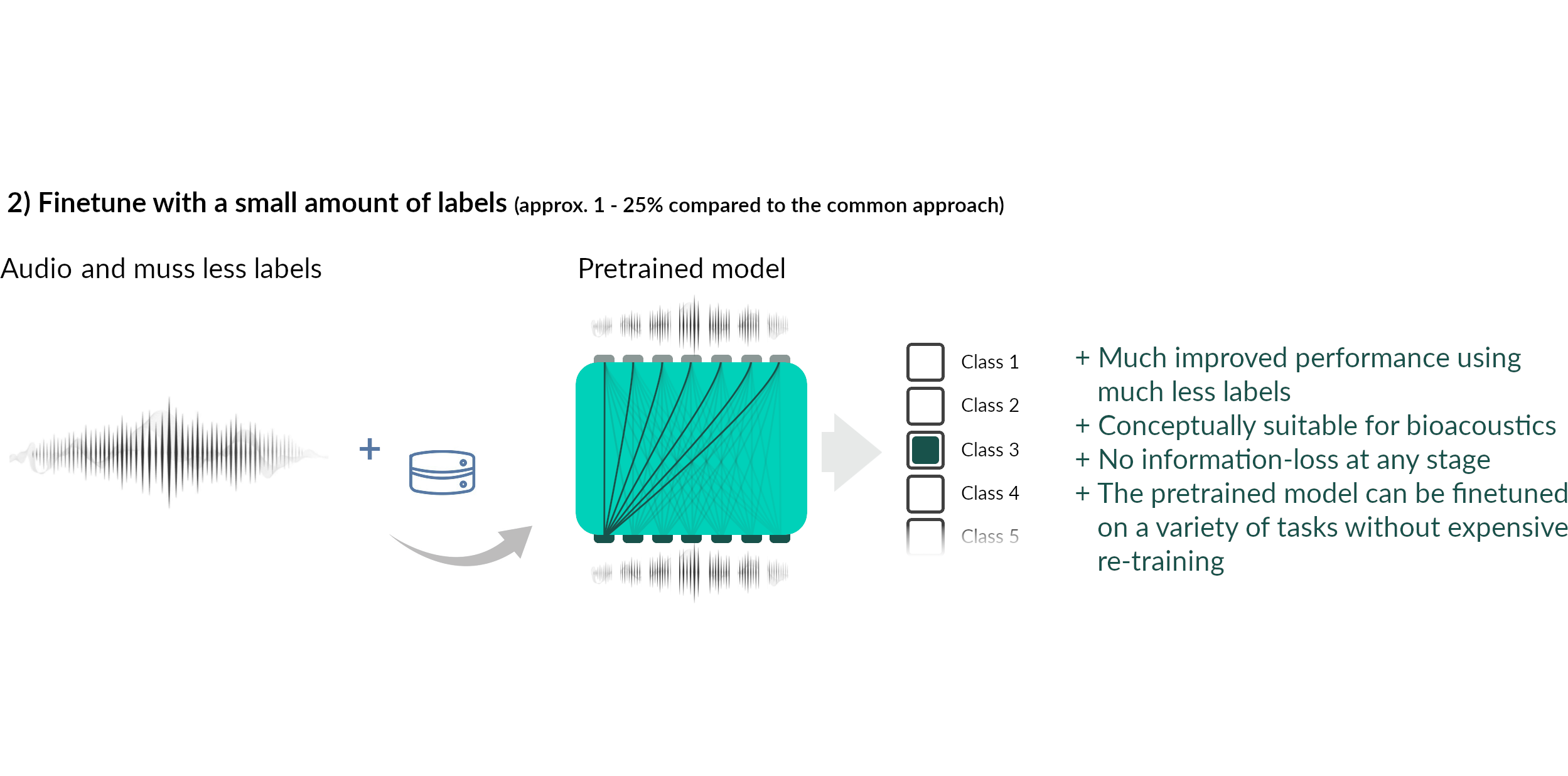
Current status
Meerkats
- MeerKAT is published at Max-Planck repository (1068h pretraining | 184h finetuning)
- animal2vec manuscript was rejected by Nature Methods, still under review at Methods in Ecology and Evolution
- By now, we have a new animal2vec finetune checkpoint using additional data from the 2022 campaign (Using a different audio recorder -> Soroka | Adds 61h for finetuning)
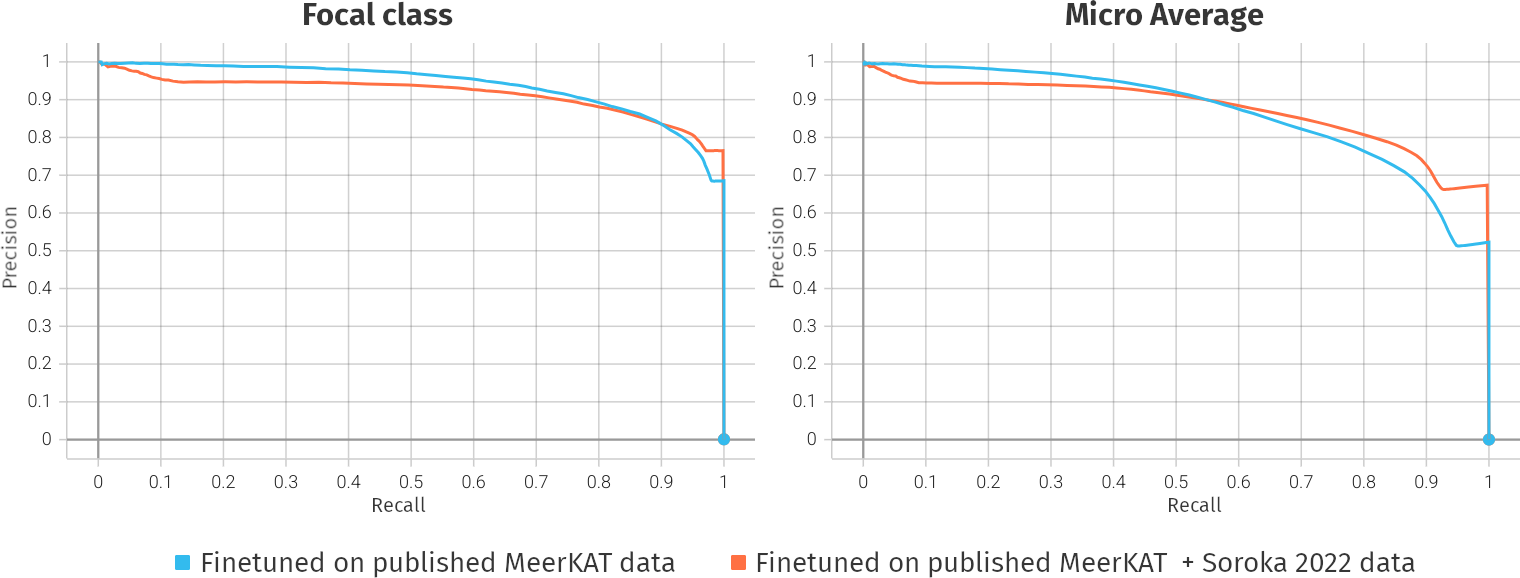
Current status
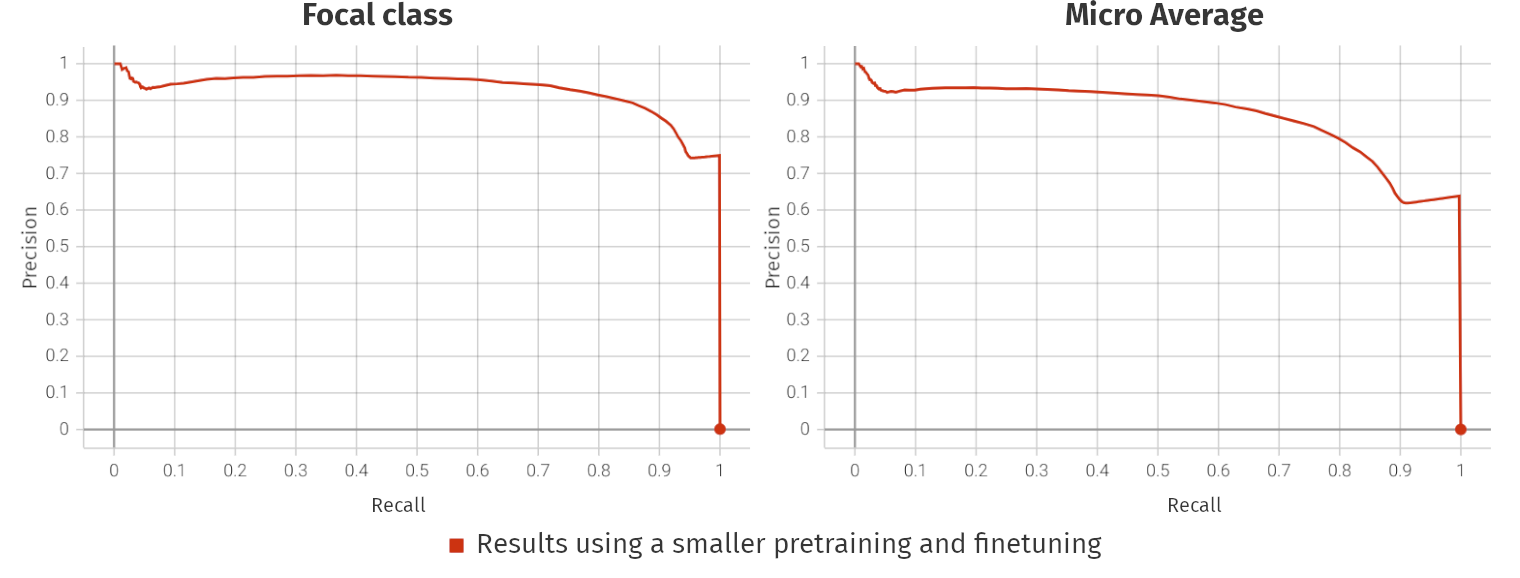
Coatis
- Preliminary results using the small model are available for Galaxy group (300h pretraining | 52h finetuning)
- Large pretraining using the large model and all groups is currently running (1805h pretraining | 92h finetuning)
Current status
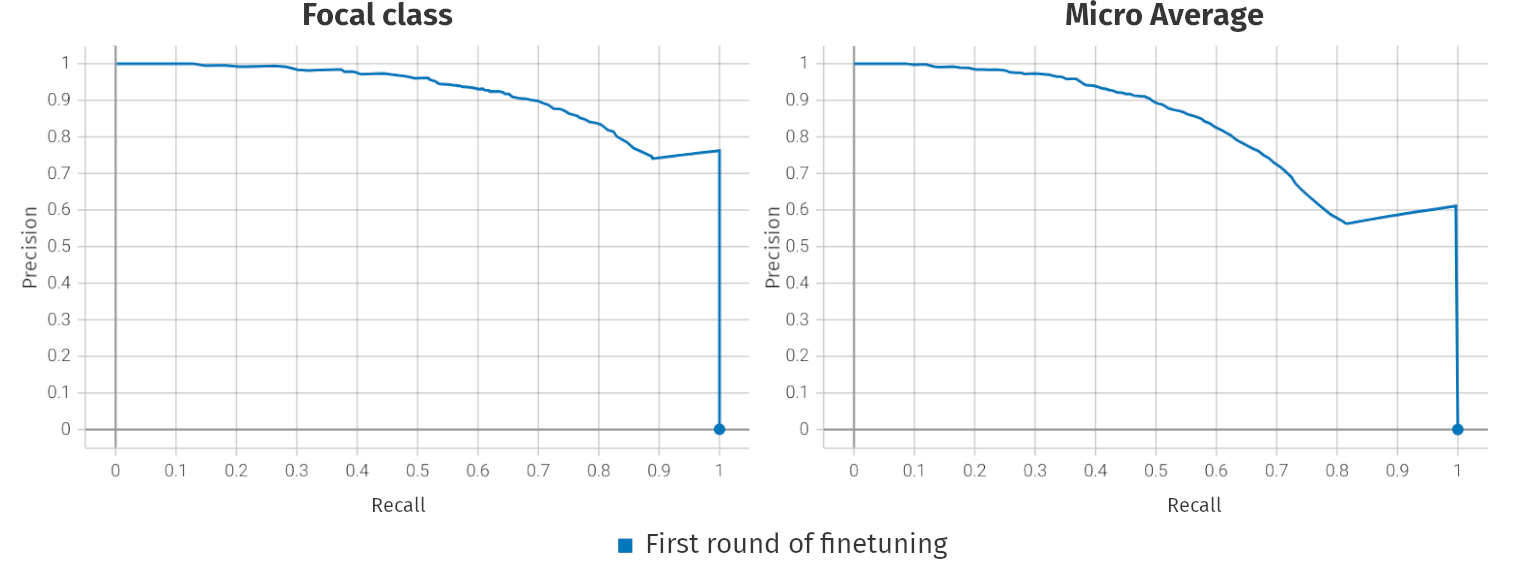
Hyenas
- Results using the small model are available (3900h pretraining | 11h finetuning)
Future plans
The idea
- Currently, we train (pretrain + finetune) new models for every species
- Computationally very expensive
- Pretraining takes a month. Finetuning, a couple of days
- What is usually done in industry is to do an extremely large-scale pretraining and then finetune with different and smaller datasets
- The broadly pretrained model is then called foundational model
- Bioacoustic researchers, regardless of the species they study, could start from such a foundational model and finetune on the data they have
Future plans
Why don't we have that already?
Sparsity: Animal vocalizations are short and rare events
- For example:
- MeerKAT [1]: 184h of labeled audio, of which 7.8h (4.2%) contain meerkat vocalizations
- BirdVox-full-night [2]: 4.5M clips, each of duration 150 ms, only 35k (0.7%) are positive
- Hainan gibbon calls [3]: 256h of fully labeled PAM data with 1246 few-seconds events (0.01%)
- Marine datasets have even higher reported sparsity levels [4]
It is very hard to train a foundational model having these levels of sparsity
[1] Schäfer-Zimmermann, J. C., et al. (2024). Preprint at arXiv:2406.01253
[3] Dufourq, E., et al. (2021) Remote Sensing in Ecology and Conservation, 7(3), 475-487.
[4] Allen, A. N., et al. (2021) Frontiers in Marine Science, 8, 607321
Future plans
Why don't we have that already?
Differing sample rates
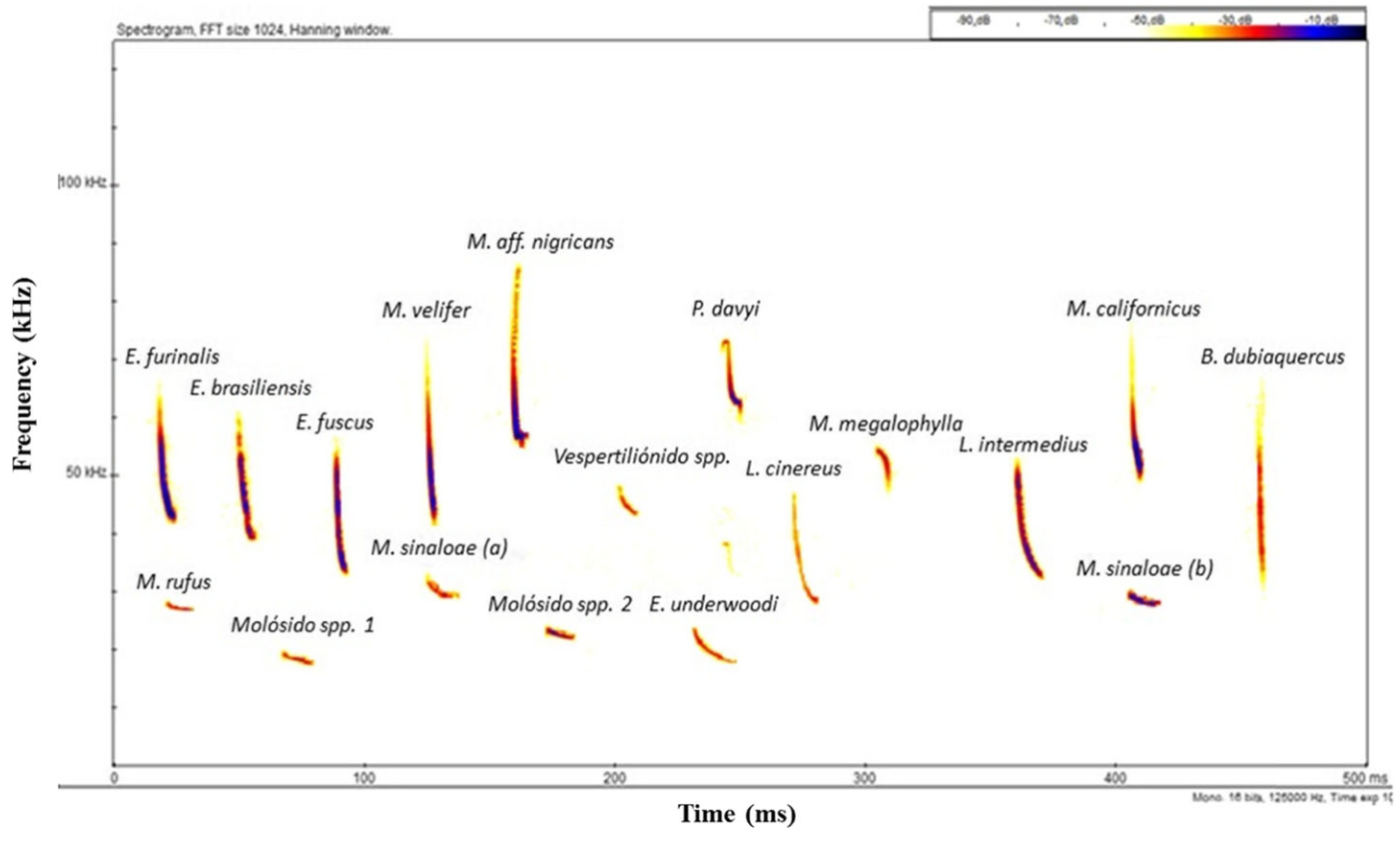
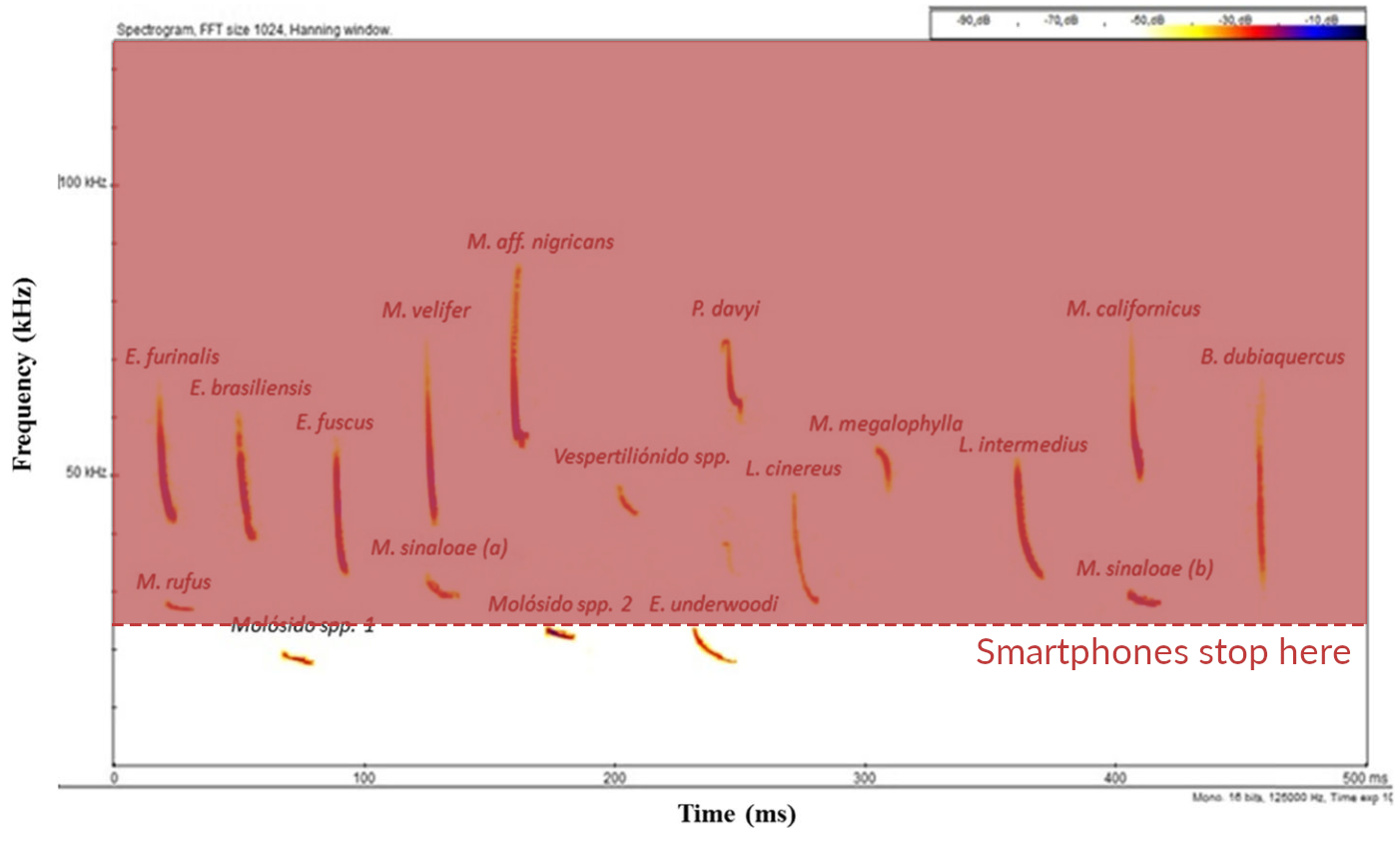
Bioacoustic signal occur over a very wide frequency range, and you need all of them
Rodríguez-Aguilar, G., et al. (2017) Urban Ecosystems, 20(2), 477–488
Status and roadmap for animal2vec 2.0
- Codewise: Full rewrite of the codebase almost done
- Hopefully brings huge improvements for train and inference speed
- Will include the sample-rate dependent positional encoding approach
- Various other technical improvements and novelties (another talk)
- Datawise: We already have a very large amount of bioacoustic data
- Everything from Xeno-Canto, iNaturalist, Tierstimmenarchiv (1.3M files -> 13k hours)
- This covers 96% of all known bird-species
- A large subset of Googles Audioset dataset (600 hours)
- Animal and Environmental sounds, plus various misc. stuff (noise, soundscapes, motor sounds, ...)
- 10-15k hours of marine data (Sanctuary Soundscape Monitoring Project (SanctSound), The William A. Watkins Collection, The Orchive, ...)
- We still have to take stock how much MPIAB data we use, but the expected order is ~10k hours
Summary
- We now have predictions for all CCAS species, and we are still working towards making them even better
- Meerkats: Current predictions are the best we can get with animal2vec
- Coati: Preliminary results are good. The best ones will be ready in 3-4 weeks
- Hyena: Pretraining status is good. Finetuning results can be improved with more labels, but are good
- We have an idea on how to tackle the domain-specific challenges in bioacoustics to build the next generation of animal2vec
- New codebase: Almost ready; Marius project will take another 1-2 months, then paper writing
- Dataset aggregation: Expected timeline is 1-2 months until everything is rudimentarily curated
- Computational resources: Will probably be provided by the Max Planck Computing and Data Facility
- Pretraining will take - in the best case - several months
Status and future plans
animal2vec
Max Planck Institute of Animal Behavior
Department for the Ecology of Animal Societies
Communication and Collective Movement (CoCoMo) Group